Python中的pandas库里的merge(),可以理解成Excel的Vlookup , 用于重复性的工作突显奇效 。如,需要很多个字段进行Vlookup时,merge()写好语句,即可自动完成 。话不多说,下面开始merge()神器 。
举的例子和上一文章一样 。【数据1.xlsx】、【数据2.xlsx】
目的:将【数据2.xlsx】的2列填充到【数据1.xlsx】
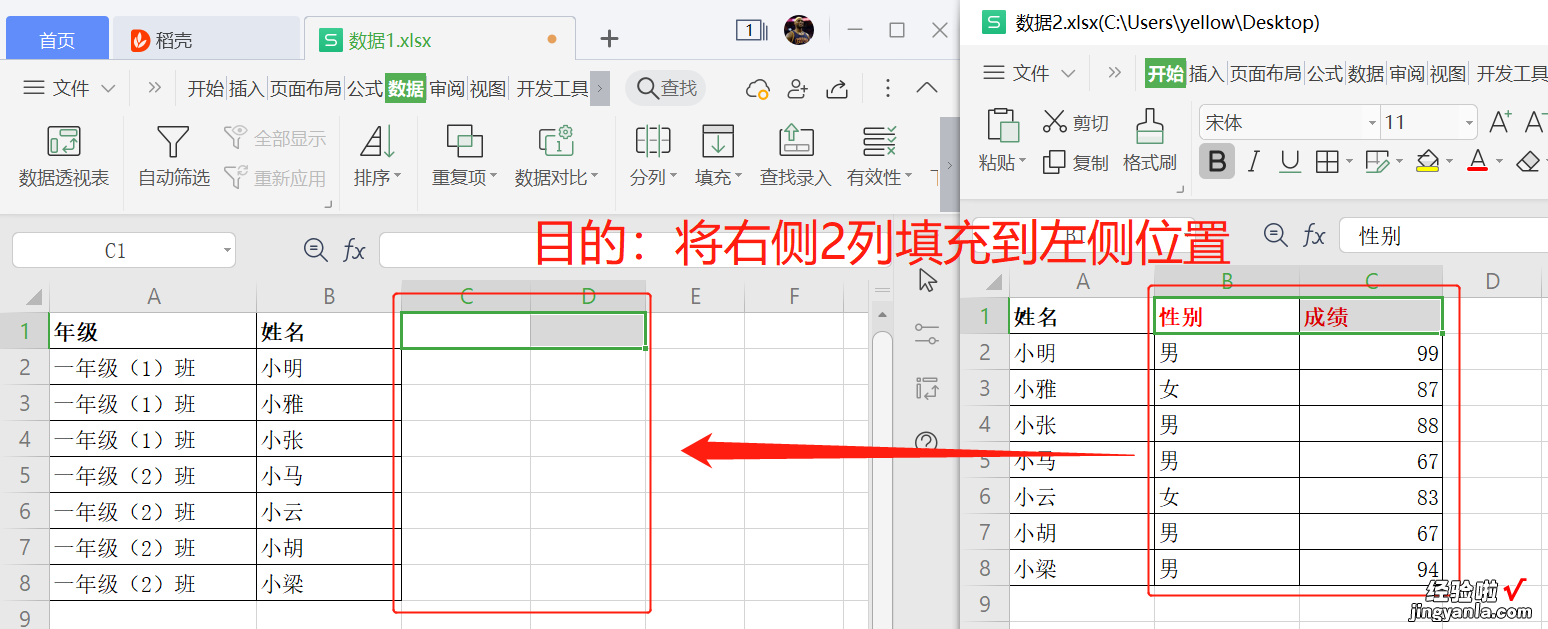
第一步:将这2个表在Python中打?。?/b>
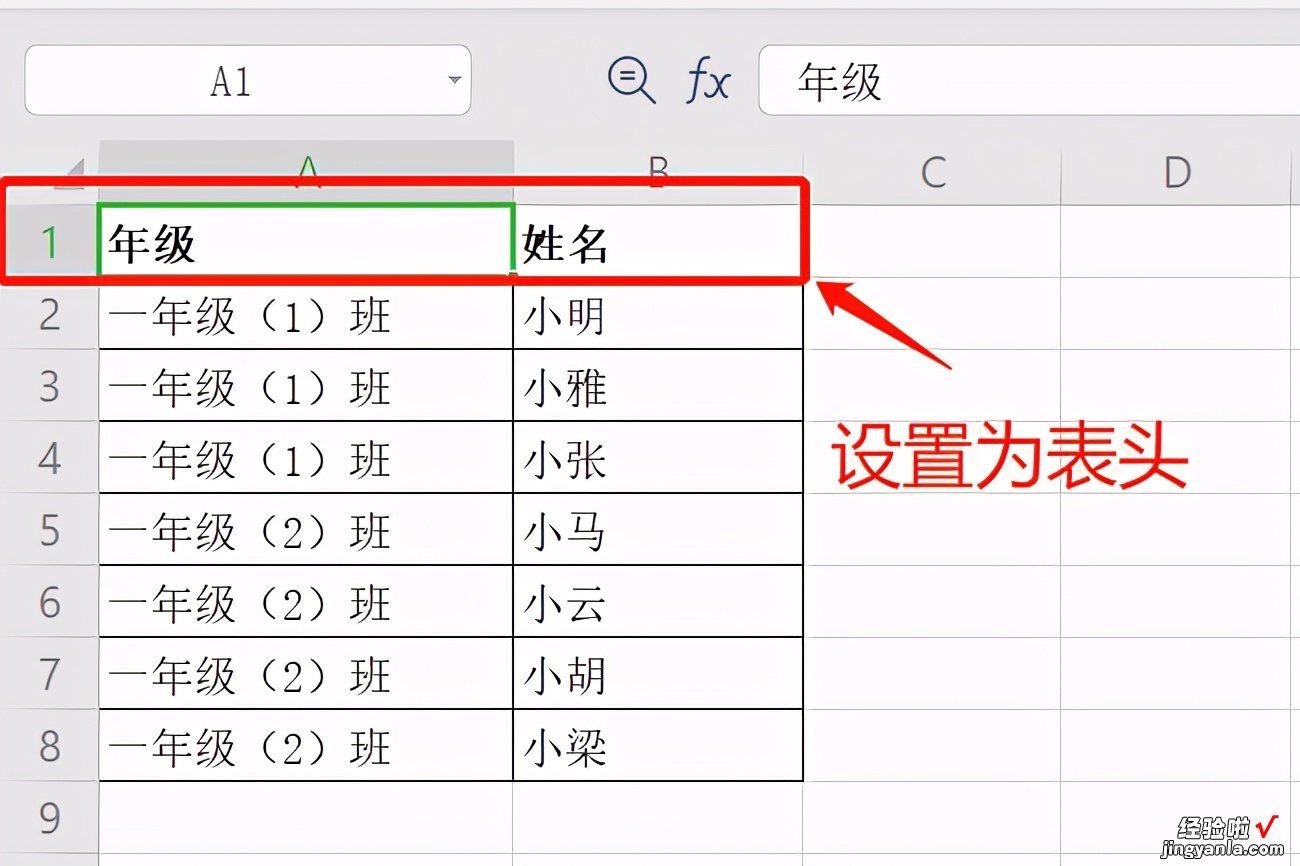
importpandas as pd地址1='C:/Users/yellow/Desktop/数据1.xlsx'地址2='C:/Users/yellow/Desktop/数据2.xlsx'data1=pd.read_excel(地址1,header=0)data2=pd.read_excel(地址2,header=0)导入pandas模块,分别读取路径里的表,header=0是以0行为表头 , 从第1行开始读取数据 。
第二步:开始使用merge()
data3=pd.merge(data1,data2,on='姓名',how='left')公式是这样的,第一次用的时候我也比较蒙圈 。data1、data2是要操作的表 。on='姓名',两个表要进行关联的相同列 。how=’left‘是将【数据2.xlsx】的数据填充到【数据1.xlsx】 。
其实on='姓名'也有其他用法,如两个表的列内容一样,但列名不一样,可以用left_on=' '、right_on=' '分别填上列名 。
data3=pd.merge(data1,data2,left_on='姓名',right_on='姓名',how='left')第三步:打印且保存新的表

data3.to_excel('C:/Users/yellow/Desktop/数据3.xlsx',index=False)将data3导出excel,得到以下表【数据3.xlsx】
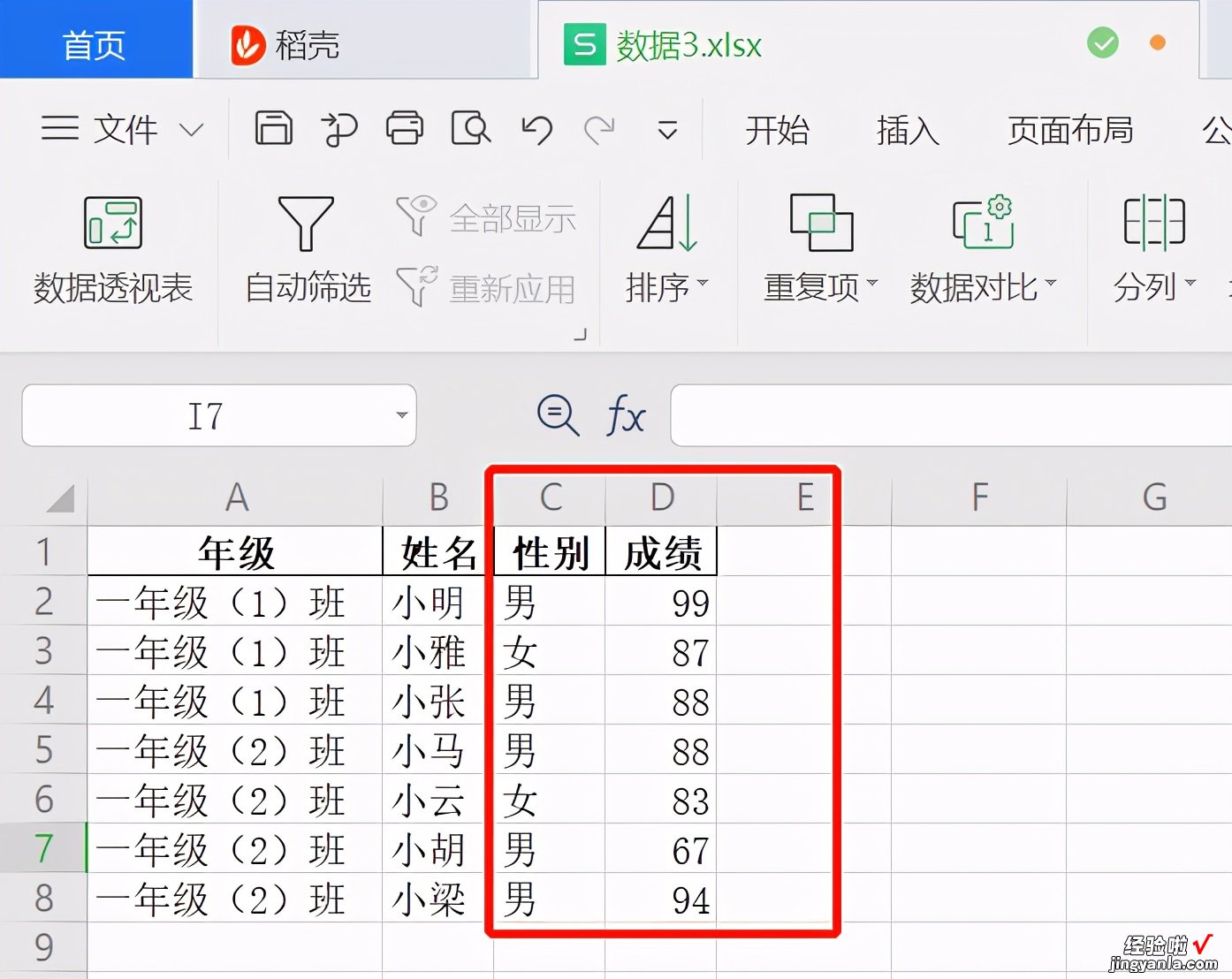
总结:
【Pandas的merge,使Excel的Vlookup效率加倍】用merge(),其实写好了代码,就能重复使用 , 不像vlookup,每次都要重新输入一次公式,比较麻烦 。merge()确实在匹配里独占优势 。欢迎评论区留言~~