在写这个的时候努力想了一下最近都在干啥呢?最近也是在努力健身(但是其实好像没有减下来体重 , 嘘~,主要是天天天天天想吃炸鸡,然后每天放假的食量...咳咳)

除此以外都在学(xiu)习(xi),其实只是最近几天图书馆开始解封了就溜出来吹吹空调看看闲书啦~然后么前几天想着去做一些简单的外包去赚点钱吧!毕竟第一生产力就是搞钱

当天晚上就去猪八戒网投标......开开心心投了13块 , 结果一个标都没中还被平台吞了8块钱555~感觉心中的一团热火被浇了液氮 。(猪八戒网属实坏!)
最后,还是想着好好学习吧 , 最近看了爬虫又新做了个小作品,来瞅瞅吧~~~
正文开始
因为最近想买ipad,所以想要尝试一下吧淘宝上所有ipad商品做一个统计,把所有ipad商品的信息集合到一个excel里,那么使用爬虫这个程序也是可以实现的 。
首先我们使用Chrome浏览器打开淘宝,输入心心念念的ipad , 搜索后能一整页的商品,然后我们按F12进入开发者模式
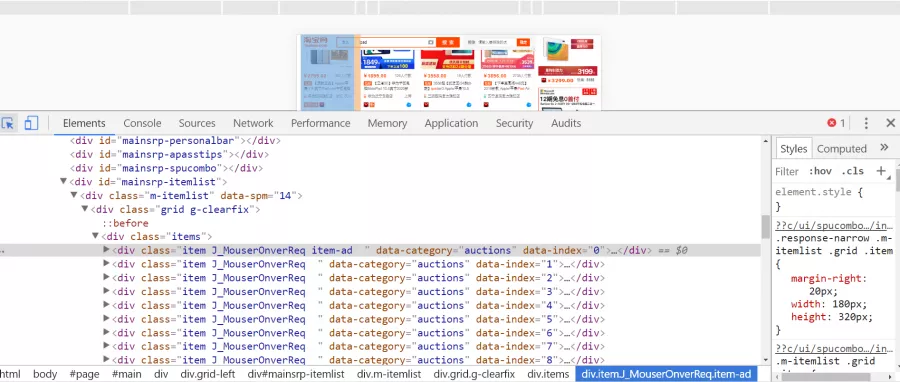
然后我们可以看见源码里有那一排的item , 其实每一个item都对应着一个商品 。
既然源码可以是直接得到的(这么说是因为有的网页源码并不能直接看到),那么我们就可以直接用自动化测试工具selenium去自动化得获得网页代码
简单介绍一下这个工具,举个栗子,点击一下python程序的运行按钮,电脑就直接打开浏览器 , 然后打开到淘宝页面进行搜索 。(当然前提是我们已经在代码上设计好这个流程),而这个流程只需要我们给程序一个网址链接 。
通过尝试了解到在淘宝的链接就是"https://s.taobao.com/search?q=(后面再跟上要搜索的商品名)",那么selenium就可以自动打开那个网页 , 其实这种常见的话就是那些所谓的秒杀软件,电脑可以自动输入账号密码,如果计算机会说话:

然后selenium在打开网页的同时也可以获取网页的源代码,也可以去点击下一页 。那么这样的话我们定位到那个下一页按钮 , 让这个selenium去点一下,就可以获取全部的商品源代码啦
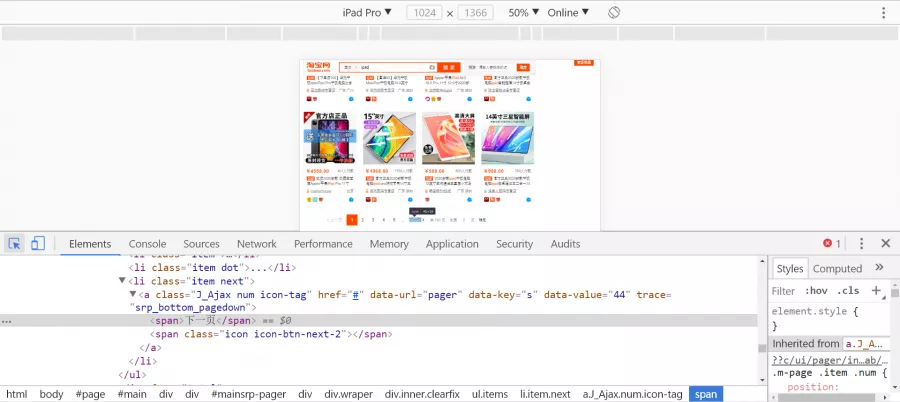
最后我们通过pyquery解析库把有用的信息从源码里面提取出来 , 然后再制作成一个EXCEL可以啦~
最后的成品大概就是这样的啦~
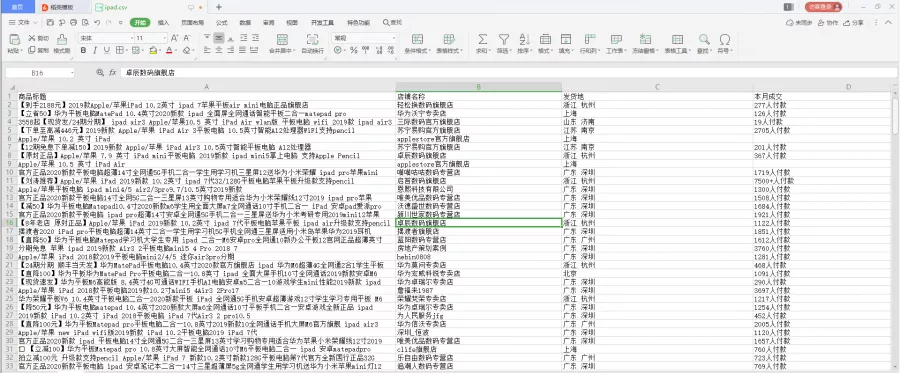
我们可以对其中的数据进行分析就好啦