- 解析数据
- 我们需要使用BeautifulSoup这个功能模块来把充满尖括号的html数据变为更好用的格式 。
- from bs4 import BeautifulSoup这个是说从(from)bs4这个功能模块中导入BeautifulSoup,是的,因为bs4中包含了多个模块,BeautifulSoup只是其中一个 。
- soup = BeautifulSoup(html.text, 'html.parser')这句代码就是说用html解析器(parser)来分析我们requests得到的html文字内容,soup就是我们解析出来的结果 。
- For循环
- 豆瓣页面上有25部电影,而我们需要抓取每部电影的标题、导演、年份等等信息 。就是说我们要循环25次,操作每一部电影 。for item in soup.find_all('div',"info"):就是这个意思 。
- 首先我们在豆瓣电影页面任意电影标题【右键-检查】(比如“肖申克的救赎”),打开Elements元素查看器 。
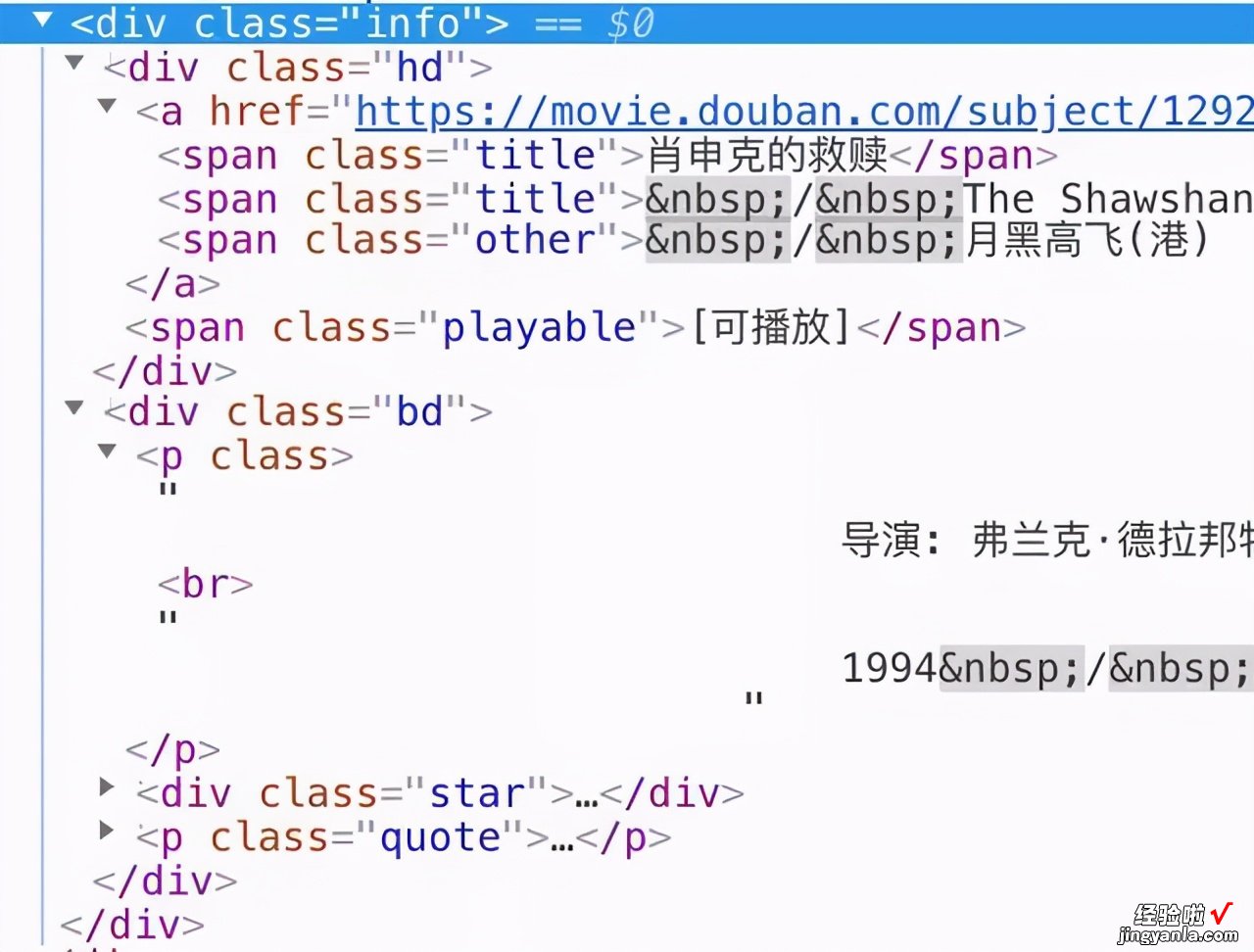
find_all('div',"info"),find是查找,find_all就是查找全部,查找什么呢?查找标记名是div并且class属性是info的全部元素,也就是会得到25个这样的元素的集合 。
for item in 集合:的含义就是针对集合中的每个元素,循环执行冒号:后面的代码 , 也就是说,下面的几行代码都是针对每部电影元素(临时叫做item)执行的.
- 获取电影标题
- title=item.div.a.span.string中item代表的是上面图片中的整个div元素(class='info'),那么它下一层(子层)div再下一层a再下一层span(class='title'的)里面的文字“肖申克的救赎”就是我们需要的电影标题,所以是.div.a.span然后取内容.string

注意,一层层地点下去的方法只适合于获取到每层的第一个元素,比如前面图中我们知道实际有三个span,其他两个英文名、其他译名 , 但我们只取到第一个 。
- 获取年份段落
.contents[2]是取得这一行第3个文字小节,content单词是内容的意思,
标记将整个p标记内容分成了三段(0段,1段,2段) 。
br将contents内容分为三段
所以,yearline=item.find('div','bd').p.contents[2].string这句话得到的是1994 / 美国 / 犯罪 剧情这行,但实际上它还包含了很多空格和回车换行符号的 。所以我们再使用两个replace替换掉空格和回车 。replace是替换的意思,在数据里n是表示换行回车 。
yearline=yearline.replace(' ','') #去掉这一行的空格yearline=yearline.replace('n','') #去掉这一行的回车换行- 获取年份数字
- 经过上面的处理,我们得到了干净的1994 / 美国 / 犯罪 剧情 , 我们只要截取前面4个数字就可以了,也就是从第0个字符截取到第4个字符之前(0,1 , 2,3) , 我们使用year=yearline[0:4]就可以实现 。
- 输出和复制到excel
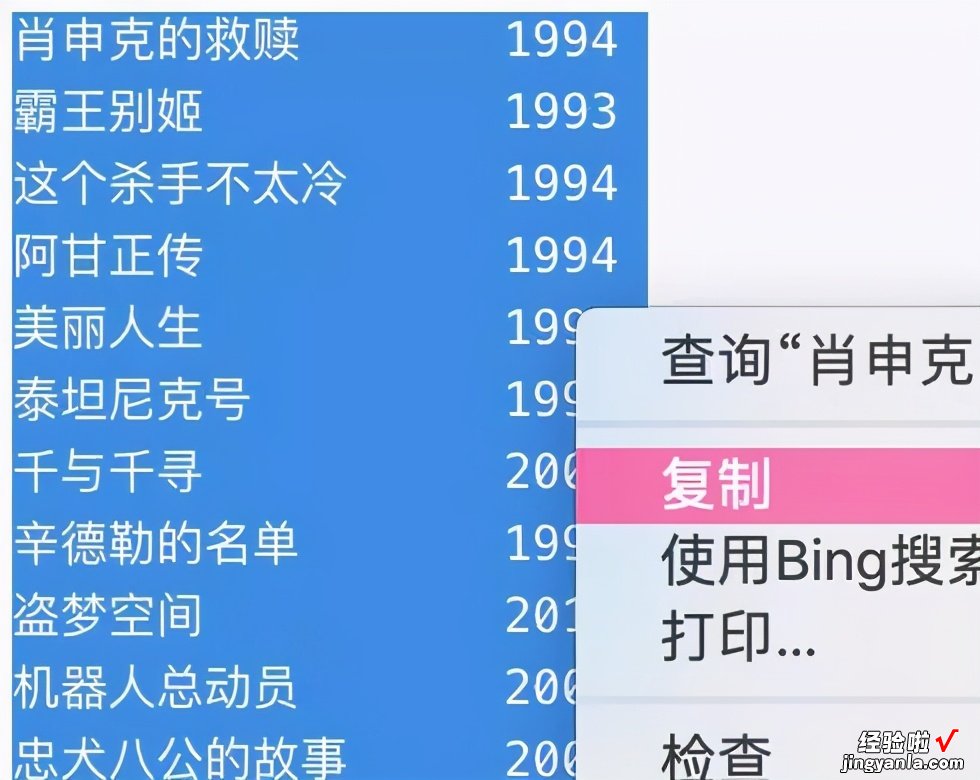
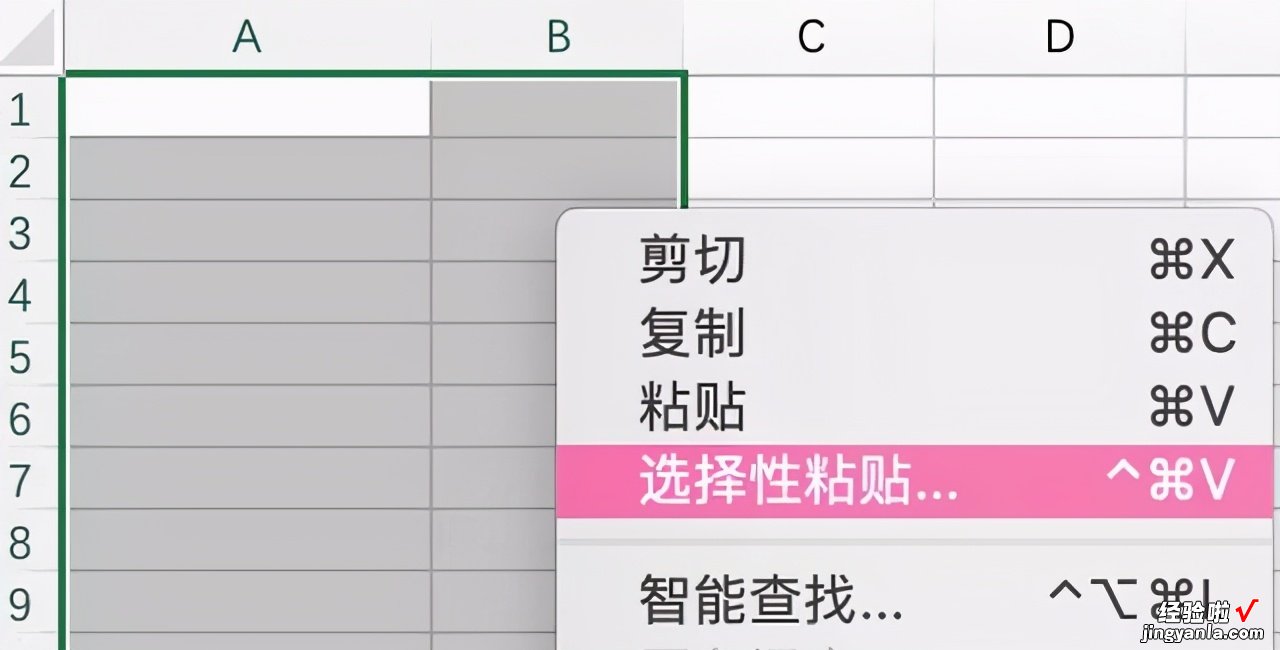
- print(title,'t',year),中间的't'是制表符,我们可以直接鼠标选择output输出的内容,右键复制,然后打开excel新建空白文件,然后选择合适的表格区域范围,【右键-选择性粘贴】弹窗中选择Unicode文本 , 就可以把数据粘贴到excel表格中 。
3. 采集更多电影
上面代码只是帮我们输出第一页25部电影信息,要采集第二页可以把requests请求的链接地址更换一下html=requests.get('https://movie.douban.com/top250?start=25') , 每页25个递增,第三页就是start=50,以此类推 。
最后把全部250个电影数据反复10遍粘贴到Excel表格就可以了 。
当然我们有更好的方法 , 比如利用for循环自动采集10个页面的数据 。
import requestsfrom bs4 import BeautifulSoupstart=0for n in range(0,10): html=requests.get('https://movie.douban.com/top250?start=' str(start)) start =25 soup = BeautifulSoup(html.text, 'html.parser') for item in soup.find_all('div',"info"): title=item.div.a.span.string #获取标题 yearline=item.find('div','bd').p.contents[2].string #获取年份那一行 yearline=yearline.replace(' ','') #去掉这一行的空格 yearline=yearline.replace('n','') #去掉这一行的回车换行 year=yearline[0:4] #只取年份前四个字符 print(title,'t',year)这是把刚才的几乎全部代码放到了新的循环里面for n in range(0,10):里面 。range(0,10)就是生成一个0~9的集合 。另外,每次requests请求之后我们还添加了start =25这行,就是每次叠加25的意思,第一次循环start是0,然后加25变25,第二次就是25,然后加25变50,以此类推 。
运行这个代码,稍等一下运行结束,就能看到output全部250部电影信息了 。
4.生成统计数据
我们把采集到的数据粘贴到Excel文件中,最顶上插入一行【影片名、年份】 。
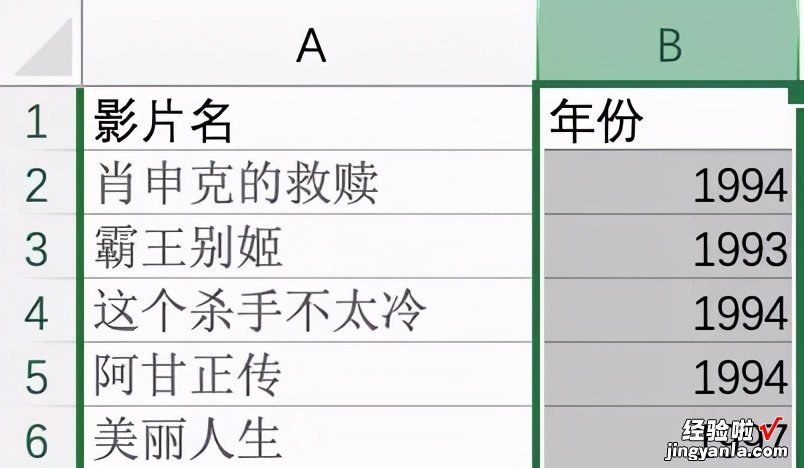
Excel数据
接下来我们利用这些数据研究一下哪些年盛产好电影 。
如上图,点击B栏全选这一列 。然后选择【插入-数据透视表】
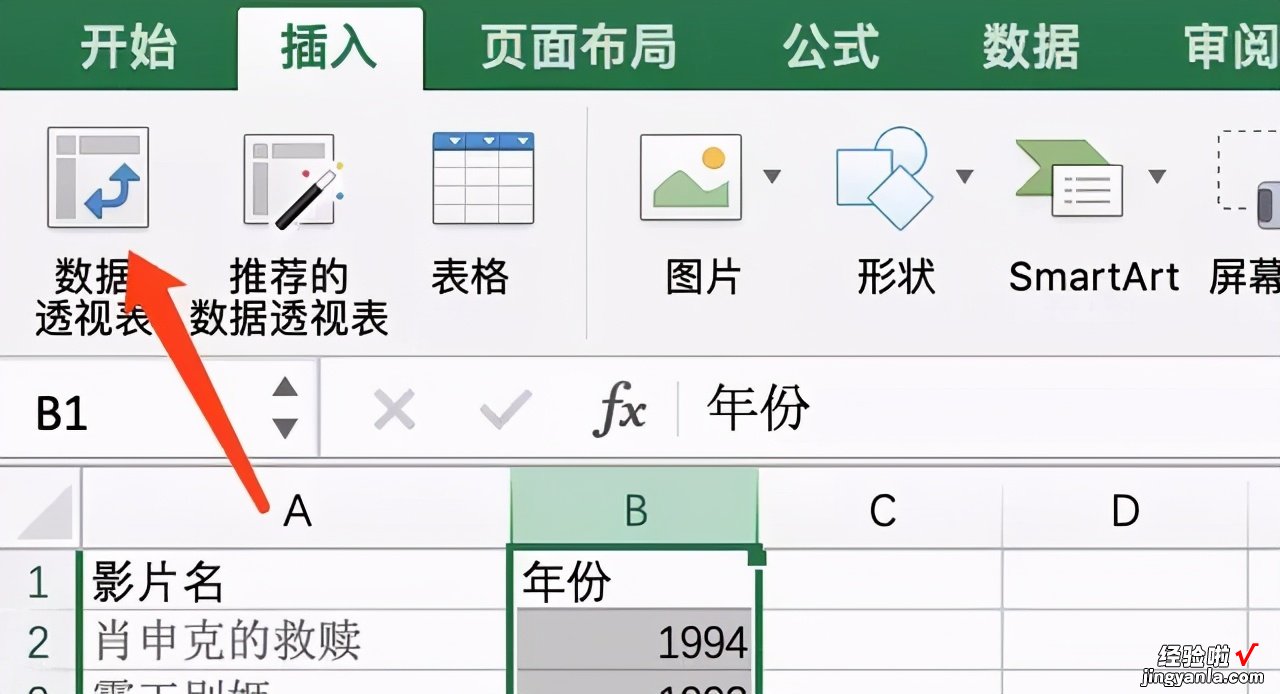
插入数据透视表
然后弹窗中选择【新工作表】,其他保留默认,点确定 。
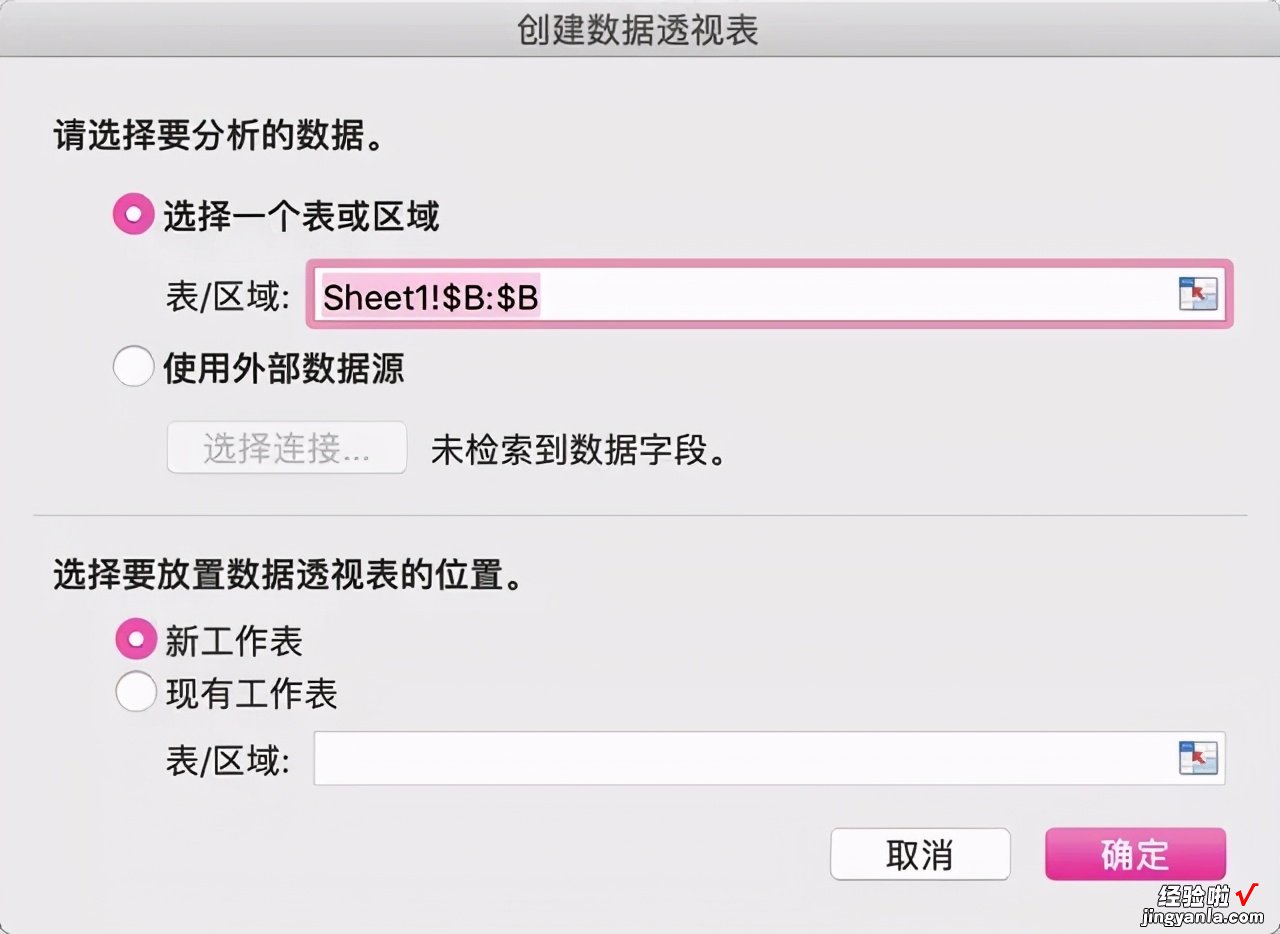
创建数据透视表
然后在右侧把年份拖拽到下面的行中 。
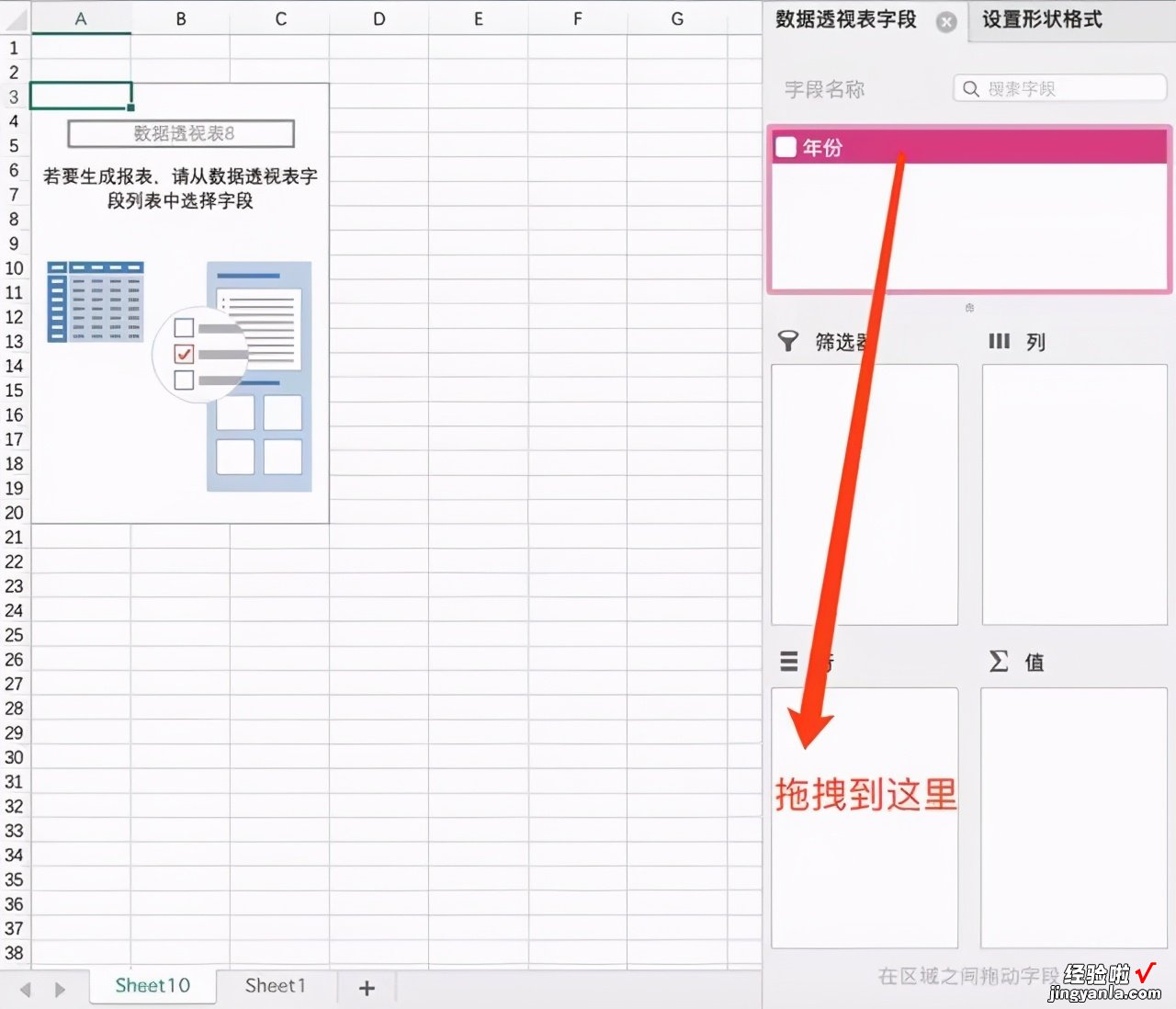
拖拽到行
同样再拖拽到值里面 。

拖拽到值
然后点击表格里面的【求和项:年份】,再点击【字段设置】,弹窗中选择【计数】 , 然后确认,就能统计出每个年份上映的电影数量 。
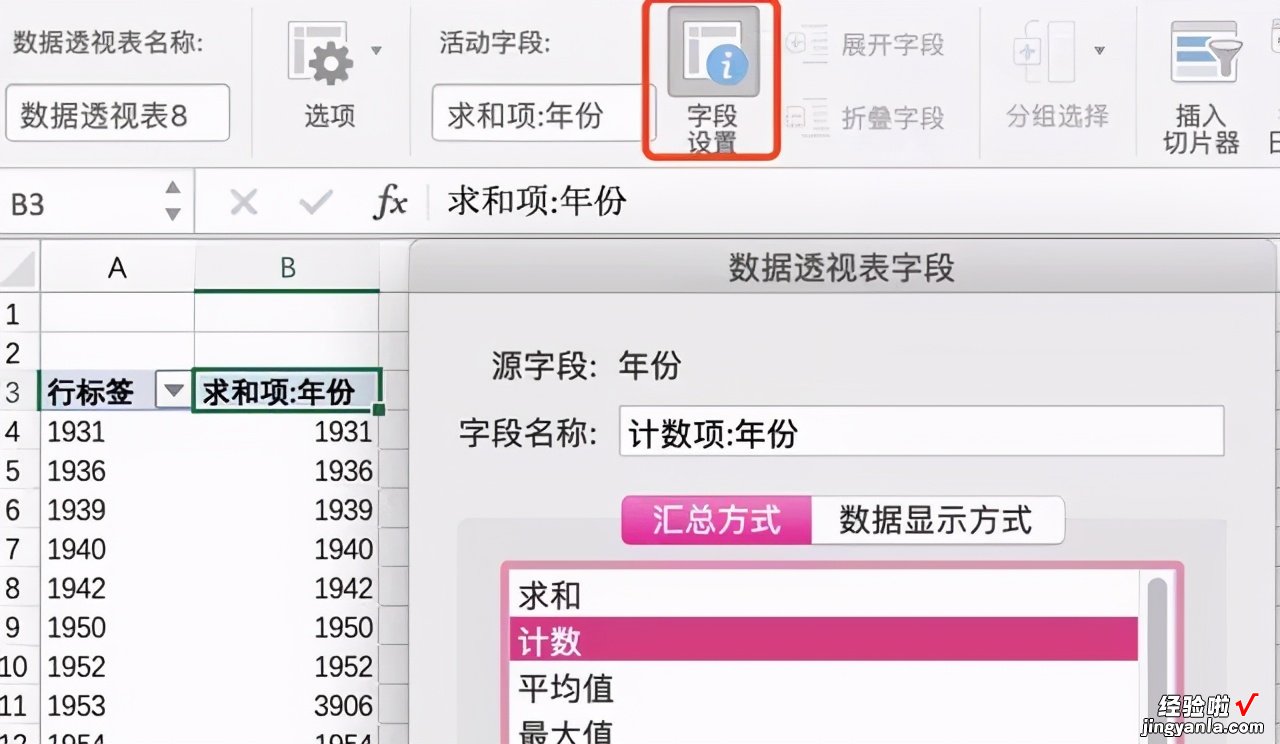
很多年份都是1或2 , 但表格滚动到下面就会看到1994、1995哪些年上映的电影比较多 。

选择AB两栏,然后点击【插入-柱形图图标】,就能得到最终的统计图 。
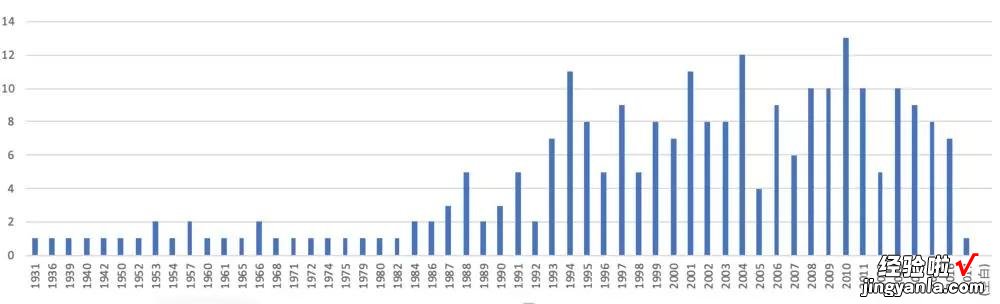
最终统计图如下 , 可以清楚地看到全球最佳电影的年份分布情况,可以得到一些结论 , 比如上个世纪90年代初开始电影制作水平有了明显的提升,至90年代中期以后,虽然一直处于较高水平,但没有太大幅度的提高了;2010年贡献了最多数量的好电影,此后至今的8年虽然佳片不断(12年除外),但整体走低,2017年观众认可度达到最低点 。
全球佳片历史分布
文章到这里就结束了 , 喜欢的小伙伴可以点个关注,点个赞~
需要下面这些资料的,可以加微信mss99887
【Python爬虫案例详解:爬取电影top250写入Excel】或者私信我哦