原计划这篇文章在一月前发表,但最近生活上出了点状况 。不管有没有人关注过我的文章,希望将来能帮助遇到过同样问题的你 。本人所有的文章均为原创,转载请说明出处,谢谢 。前一篇的文章中我们已经能够 , 并生成格式化的json数据 。在后续的工作中又陆续出现了一些问题,在此记录并解决问题 。今天我们将围绕这些问题展开讨论,而很多问题可以在PyMuPDF的官方「链接」中找到答案,有兴趣的小伙伴可以直接阅读官方文档 。
问题一
在前一篇文章的末尾介绍过,对于延长线条get_small_cell函数会依据表格四边黑点的坐标重新绘制线条,实现覆盖所有表格格子,但针对下图的【付款方】和【收款方】的格子检测却存在问题 。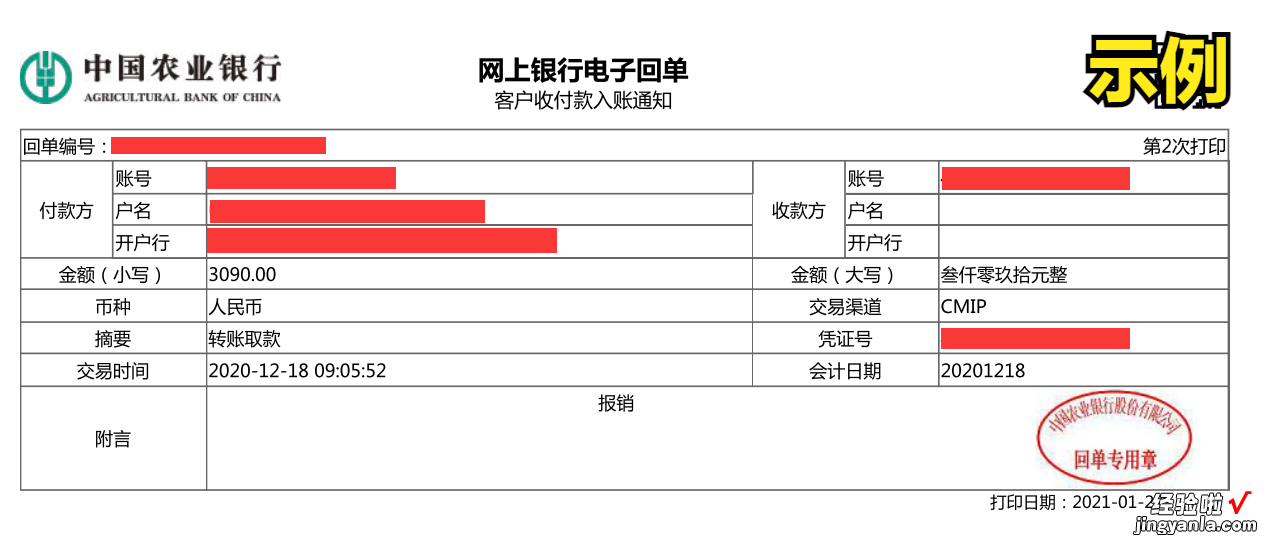
上篇文章不能处理的表格类型
解决方案:
绘制线条时,延长每根线条的长度,使其达到表格边缘 。

依据线条绘制的表格
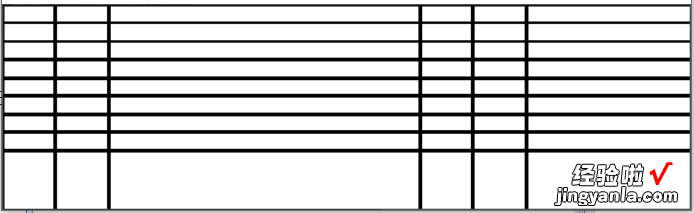
延长每根线条,使其达到表格边缘
问题二
在处理【问题一】的同时,我们也应当警惕那些不规范格式的表格的出现 。例如
不规范格式的表格
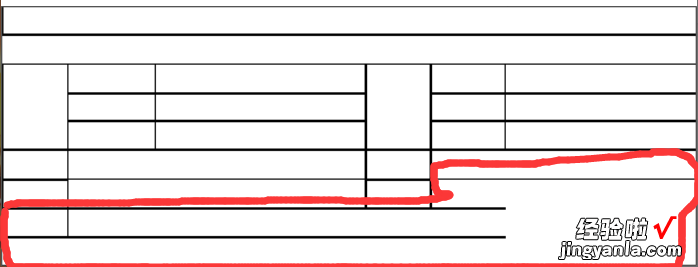
不规范格式的表格提取线条后
延长线条后
此问题在表格格子检测时 , 将图二中红色区域变为一个整体格子 。针对此类问题,暂无良好的解决方案 。在思考的同时,可以考虑以下两个方案 。一,将红色区域视同为一个整体;二,检测线条端点是否与其他线条相交,如若未相交 , 则延长线条直至与其他线条接触 。
问题三
依据fitz.fitz.Page.getDrawings函数返回的线条和矩形信息,与pdf阅读器表格图像对比 , 出现了一些额外的线条
实际的表格
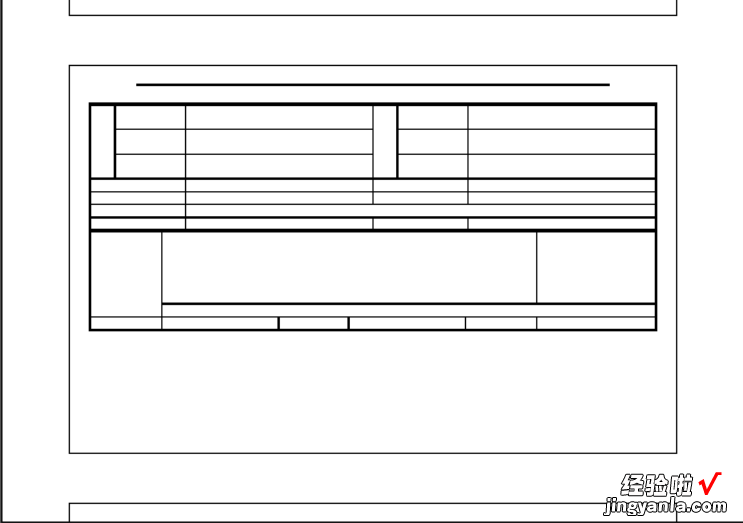
在绘制线条中 , 出现了额外的线条
解决方案:
参考官方文档,线条有填充颜色和边框颜色 。当线条的填充颜色和边框颜色都与背景色一致时,自然看不到线条 。
问题四
【利用cv2提取pdf中的表格】文字坐标和实际显示的坐标出现90度、180度、270度旋转 。解决方案:
参考官方文档page中有旋转角度属性,只需根据此属性旋转角度即可 。
问题五
明显文字非图片,但是却不能复制 。在利用各类解密工具后,依旧未能获取文字信息 。但是使用pywin32将pdf转为word后,能够复制文字 。代码如下import win32com.clientword_app = win32com.client.Dispatch('word.Application')pdf_path = r'xxx.pdf'pdf_doc = word_app.Documents.Open(pdf_path)out_path = r'xxx.docx'pdf_doc.ExportAsFixedFormat(out_path, 17, Item=7, CreateBookmarks=0)后续仔细观察word文件,疑似office使用OCR技术将图片转为文字,具体图片如下

内容类似OCR的识别结果
在参考PyMuPDF的官方文档时,猜测文字可能是直线加三次贝塞尔曲线绘制而成 。只是很疑惑这些曲线能将文字细节绘制如此生动

非常生动的细节描述
直到我看到了这篇如何用python写一个naive的字体渲染 - 知乎,并按文章的内容绘制出了文字 。
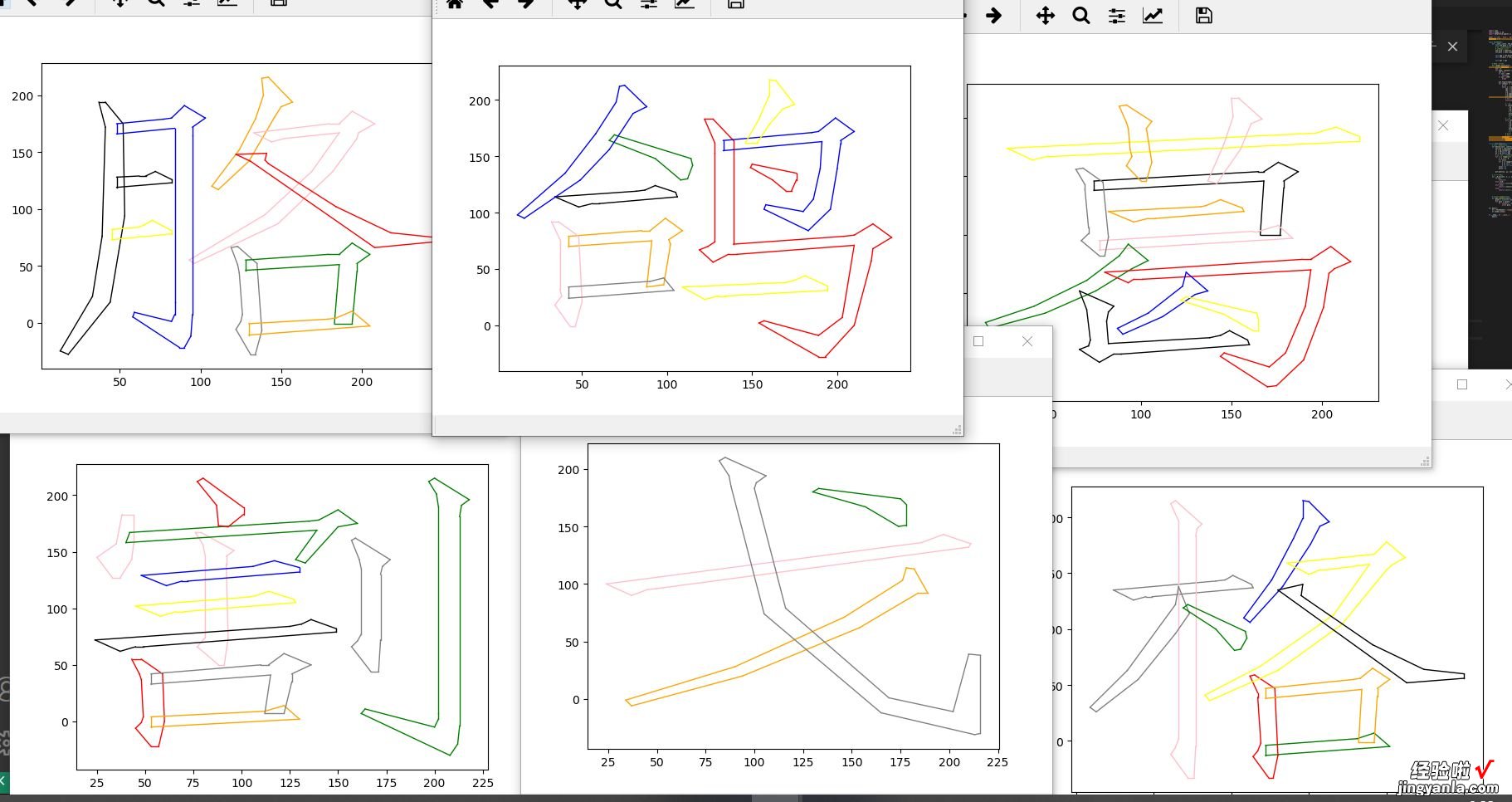
使用三次贝塞尔曲线绘制的文字
对于此类PDF , 至今我未能找到解决办法 , 如果有知道答案的小伙伴 , 希望能在评论区告诉我解决方案 。
结尾
在最后将所有修改后的代码献上import fitzimport numpy as npimport cv2import itertoolsimport copydef to_int(*kwargs):v = []for k in kwargs:v.append(int(k))return vdef page_to_words_list(page: fitz.fitz.Page) -> list:'''将每一页中的textWords信息使用list封装,这样方便后续使用:param page::return:'''# 获取文字及坐标信息words = page.getTextWords()# 将元素转为list# 因为list[0],list[1]....对于不熟悉代码的人很容易忘记含义,所以用字典封装# words = [[w[0], w[1], w[2], w[3], w[4]] for w in words]# 此处更适合用实体类,但是调试print的时候不方便,虽然可以重写__str__word_list = []for w in words:if '页码' in w[4]:continue# 有些文字旋转过,需要旋转回来p1 = fitz.Point(w[0], w[1]) * page.rotation_matrixp2 = fitz.Point(w[2], w[3]) * page.rotation_matrix# 旋转后矩形点位置发生改变,需要还原p3 = min(p1[0], p2[0]), min(p1[1], p2[1])p4 = max(p1[0], p2[0]), max(p1[1], p2[1])word_list.append({'rect': [p3[0], p3[1], p4[0], p4[1]], 'text': w[4]})# 按y坐标排序word_list = sorted(word_list, key=lambda data: (data['rect'][1], data['rect'][0]))return word_listdef draw_pdf_tables(page: fitz.fitz.Page):assert isinstance(page, fitz.fitz.Page), '必须传入fitz.Page对象'# 创建一个白色的画布pixmap = page.getPixmap(matrix=fitz.Matrix(1, 1))# 二进制数据,宽,高img = np.zeros([pixmap.h, pixmap.w], dtype=np.uint8)255draws = page.getDrawings()# 在白色的画布上,画上黑色的线条for draw in draws:color = draw['color']fill = draw['fill']if (color == [1.0, 1.0, 1.0] and fill is None) or (fill == [1.0, 1.0, 1.0] and color is None):continueitems_ = draw['items']for item_ in items_:# print(item)item_ = list(item_)# 线条if 'l' == item_[0]:p1, p2 = to_int(*item_[1]), to_int(*item_[2])img = cv2.line(img, (p1[0], p1[1]), (p2[0], p2[1]), (0))elif 're' == item_[0]:p = to_int(*item_[1])img = cv2.rectangle(img, (p[0], p[1]), (p[2], p[3]), (0))# elif 'c' == item_[0]:#print('c', item_)# else:#print(item_)# cv2.imshow('1234', img)# cv2.waitKey(0)# 使用漫水填充算法,将周围变为黑色# 这样也可以去掉单独的线条cv2.floodFill(img, None, (1, 1), (0), cv2.FLOODFILL_FIXED_RANGE)kernel = cv2.getStructuringElement(cv2.MORPH_RECT, (3, 3))img = cv2.morphologyEx(img, cv2.MORPH_OPEN, kernel, iterations=2)return imgdef get_table_words(page: fitz.fitz.Page, words=None):''':param page:一页pdf:param words:从pdf中提取的无序文字:return:'''assert isinstance(page, fitz.fitz.Page), '必须传入fitz.Page对象'if words is None:words = page_to_words_list(page)img = draw_pdf_tables(page)# 查找相应的轮廓 , 得到每个表格cell的矩形框contours, hierarchy = cv2.findContours(img, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)table_cell = []# 判断文字是否在表格cell中for c in contours:r = cv2.boundingRect(c)r = [r[0], r[1], r[0]r[2], r[1]r[3]]ws = []for word in words[:]:w = word['rect']center = [(w[0]w[2]) / 2, (w[1]w[3]) / 2]if inside_rectangle(center, r):ws.append(word)table_cell.append({'rect': r, 'words': ws})# 闭运算kernel = cv2.getStructuringElement(cv2.MORPH_RECT, (3, 3))morp = cv2.morphologyEx(img, cv2.MORPH_CLOSE, kernel, iterations=3)# 查找相应的轮廓 , 得到每个表格cell的矩形框contours, hierarchy = cv2.findContours(morp, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)tables = []for c in contours:r = cv2.boundingRect(c)r = [r[0], r[1], r[0]r[2], r[1]r[3]]tables.append(r)# 排序table_cell = sorted(table_cell, key=lambda data: (data['rect'][1], data['rect'][0]))tables = sorted(tables, key=lambda data: (data[1], data[0]))# 将cell合并到表中tables_words = []for t in tables:table = {'rect': t, 'cell': []}for cell in table_cell:c = cell['rect']center = [(c[0]c[2]) / 2, (c[1]c[3]) / 2]if inside_rectangle(center, t):table['cell'].append(cell)tables_words.append(table)return tables_words, imgdef inside_rectangle(point, rect):'''判断点是否在框内:param point::param rect::return:'''x, y = point[0], point[1]x1, y1, x2, y2 = rectif x1 <= x <= x2 and y1 <= y <= y2:return Truereturn Falsedef get_small_cell(table_word, img):'''将复杂格式的表格生成最小单元的表格此方法是根据四周的点来确定最小单位的表格信息 , 但是不能避免极端情况:param table_word::param img::return:'''t_r = table_word['rect']table_img = copy.deepcopy(img)cells = table_word['cell']# 将每个格子的线条都撑到最大for cell in cells:r = cell['rect']table_img[:, r[0] - t_r[0]] = 0table_img[:, r[2] - t_r[2]] = 0table_img[r[1] - t_r[1]] = 0table_img[r[3] - t_r[3]] = 0# cv2.imshow('img',img)# cv2.imshow('get_small_cell', table_img)# 开运算,避免细小漏洞kernel = cv2.getStructuringElement(cv2.MORPH_RECT, (3, 3))table_img = cv2.morphologyEx(table_img, cv2.MORPH_OPEN, kernel, iterations=3)# cv2.imshow('morphologyEx', table_img)# cv2.waitKey(0)# cv2.destroyAllWindows()cells = []# 查找相应的轮廓,得到每个表格cell的矩形框contours, hierarchy = cv2.findContours(table_img, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)for c in contours:r = cv2.boundingRect(c)r = [r[0]t_r[0], r[1]t_r[1], r[0]r[2]t_r[0], r[1]r[3]t_r[1]]cells.append(r)cells = sorted(cells, key=lambda data: (data[1], data[0]))cells_group = itertools.groupby(cells, key=lambda x: (x[1]))return cells_groupdef equal_rect(r1, r2, border):if abs(r1[0] - r2[0]) < border and abs(r1[1] - r2[1]) < borderand abs(r1[2] - r2[2]) < border and abs(r1[3] - r2[3]) < border:return Truereturn Falsedef table_parse(table, img, border=5):'''解析表格,形成最终的表格数据:param table::param img::return:'''table_cell = table['cell']# 延长表格中的线条,获取到最小的单元格,并按行分组cells_group = get_small_cell(table, img)# i为行坐标for i, (k, line_cells) in enumerate(cells_group):line_cells = list(line_cells)# j为列坐标for j, c in enumerate(line_cells):for cell in table_cell:center = [(c[0]c[2]) / 2, (c[1]c[3]) / 2]'''如果最小单元格的格子中心 , 落在表格中,那么他一定是属于这个表格的因为上文中已经对所有的格子做了x,y轴排序 , 此处只需对比当前格子和上一个格子的位置关系,就能确定跨行跨列的相关信息inside是指cell中内部的上一次遇到的表格'''if inside_rectangle(center, cell['rect']):# if i == 6:#print('1234')r = cell['rect']# 起点或者两个框相等if equal_rect(r, c, border) or (abs(r[0] - c[0]) < border and abs(r[1] - c[1]) < border):cell['col'], cell['row'] = j, icell['colspan'], cell['rowspan'] = 1, 1cell['inside'] = celif 'inside' in cell:# 纵坐标差不多,表示同一行if abs(cell['inside'][1] - c[1]) < border:cell['colspan']= 1cell['inside'] = c# 下面格子顶坐标和上面格子底坐标elif abs(cell['inside'][3] - c[1]) < border:cell['rowspan']= 1cell['inside'] = celse:print(r, c, cell['inside'], i, j)breakif __name__ == '__main__':path = r'E:temp603回单1.pdf'# 加载pdf文件doc = fitz.open(path)# 取第一页数据page = doc[0]# 获取第一页中所有的表格文字table_words, img = get_table_words(page)# 获取第一个表格table = table_words[0]# 将表格的数据table_parse(table, img)# 测试,显示表格img = cv2.cvtColor(img, cv2.COLOR_GRAY2BGR)table_cell = table['cell']for cell in table_cell:p = cell['rect']print(cell)cv2.rectangle(img, (p[0], p[1]), (p[2], p[3]), (0, 255, 0))cv2.imshow('123', img)cv2.waitKey(0)