昨天定义了所有找到内容的规则,下一步就是如何应用、对每个找到的内容进行解析 。
同样的 , 也是参照获取影片详细超链接的办法添加图片 。
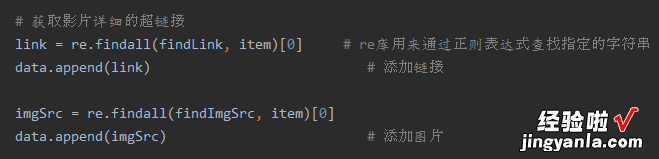
后面添加每个内容时,都要考虑其特殊性,比如添加片名,就要考虑其有可能既有中文名,又有英文名 , 所以再给其加个条件语句 。
定义两个变量 :中文标题 ctitles , 外标题 otitles 。
注意要去掉英文标题前面的斜杠,使用 replace 将斜杠替换成空格 。
另外,添加影片概述,要考虑有的片子没有概述的情况 。
添加影片相关内容时,要去掉一些不要的符合以及空格 。

最后 , 使用 datalist.append(data),把处理好的一部电影信息放入 datalist 即可 。
打印一下,看看效果 。
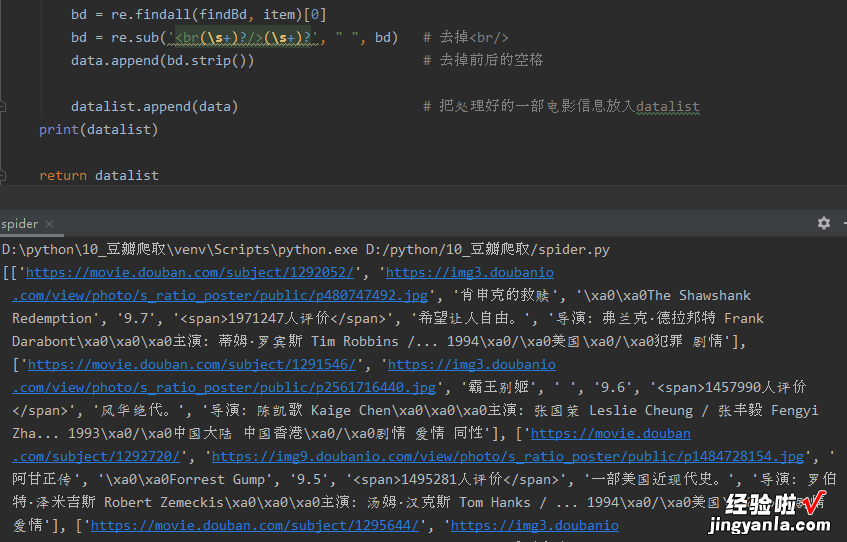
可以清楚的看到电影链接、图片链接、电影中文名、外国名、评分、评价人数、一句话概述、相关信息介绍等内容全部都获取到了 。
当然,也能看到还有些符号没有去除干净,这个问题不大 。
至此,数据解析、提取工作 , 成功突破!

总结:
整个标签解析工作,使用的是 Beautiful Soup 库,它能提供一些简单的、Python式的用来处理导航、搜索、修改分析树等功能,通过解析文档为用户提供需要抓取的数据 。
我们需要的每个电影都在一个
的标签中,且每个div标签都有一个属性 class = “item” 。
soup = BeautifulSoup(html, "html.parser")这个语句,就是创建 BeautifulSoup 对象 , html为页面内容,html.parse 是一种页面解析器 。
for item in soup.find_all("div", class_="item"):这个循环,是为了找到能够完整提取出一个影片内容的项,即页面中所有样式是item类的div 。
所有内容解析后,使用了正则表达式进行提取 。
正则表达式,通常被用来检索、替换那些符合某个模块(规则)的文本 。
Python 中使用 re模块 操作正则表达式 。
这种一环套一环的感觉 , 让我想起了当初和工友搬砖的日子 。

下面就该研究如何保存数据了 。
保存数据一般有两种方式:一种是在excel里面保存,另一种是在数据库进行保存 。
先说第一种 。
使用excel表格保存,就需要利用 Python库 xlwt 将抽取的数据 datalist 写入 excel表格 。
基本思路是以 utf-8 编码创建一个excel对象 , 再由它来创建一个sheet表,接下来往单元格里写数据 , 最后保存 。

这里可以将workbook理解成一个excel文件,而worksheet理解成文件中的一个表单 。
worksheet中的单元格 , 本质上就是一个矩阵 。
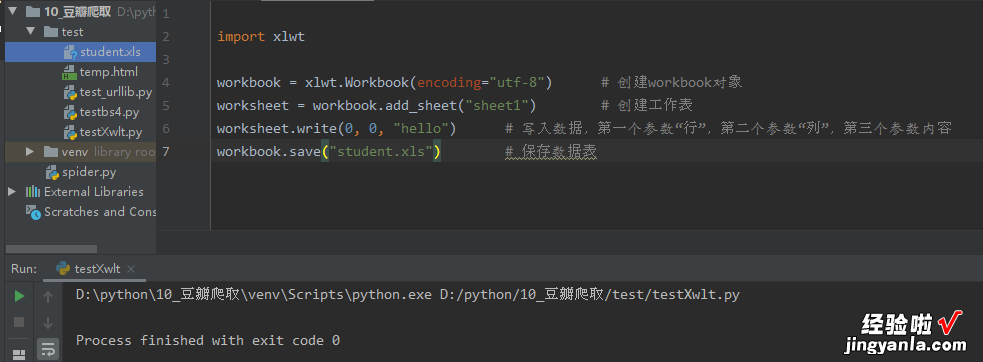
可以看到左面多了一个文件 student.xls,说明我们创建成功了 。
然后这里老师留了个小作业,让结合以前学的九九乘法表,用十分钟时间,将九九乘法表保存在 student.xls 中 。
机智如我,用了15分钟,嗯 , 果然还是失败了,郁闷 。
【学习爬虫51天,我不止成功获取豆瓣top250信息,还会建excel了!】哎 , 作为40岁的老男人,果然最缺少的,就是灵性了 。