Word文档编辑器大家应该经常使用吧,大家有没有留意到它编辑功能,当我们输入一个错误的单词时,单词单面就会标红提示“拼写错误”,这个功能是怎么实现的呢?其实?。峭ü⒘斜硎迪值? ,学习了散列表原理后你就懂得这个功能的实现方式了 。
散列表
散列表的英文名叫Hash Table,一般叫散列表或哈希表,散列表用的是数组支持按照下标随机访问数据的特性,所以散列表就是数组的一种扩展,由数组演化而来,可以说,如果没有数组就没有散列表 。我用一个列子解释一下,我们去游泳馆游泳时一般都会寄存衣物,这时前台就会登记我们名字后分配一个储物柜编号卡,后面我们通过这个编号卡就能快速地找到柜子存储衣物,回去时也能快速找到柜子取回衣物 。
这里储物柜是按照编号顺序排列 , 就相当于一个数组,由于每天去游泳的人都各不相同 , 就不能每个柜子都贴上对应人的名字了 , 所以储物前就会先去前台分配一个编号,再根据编号的下标存储在数组的下标位置 。
这就是典型的散列思想 。每个去游泳的人的名字我们叫做键(key)或者关键字 。我们把前台通过名字分配储物柜号的对应过程叫作散列函数,而通过散列函数计算得到的储物柜号码叫作散列值 。
散列函数
散列函数,顾名思义,它就是一个函数,我们可以把它定义为hash(key),其中key就是元素的键 , hash(key)就是通过散列函数计算得到的散列值 。
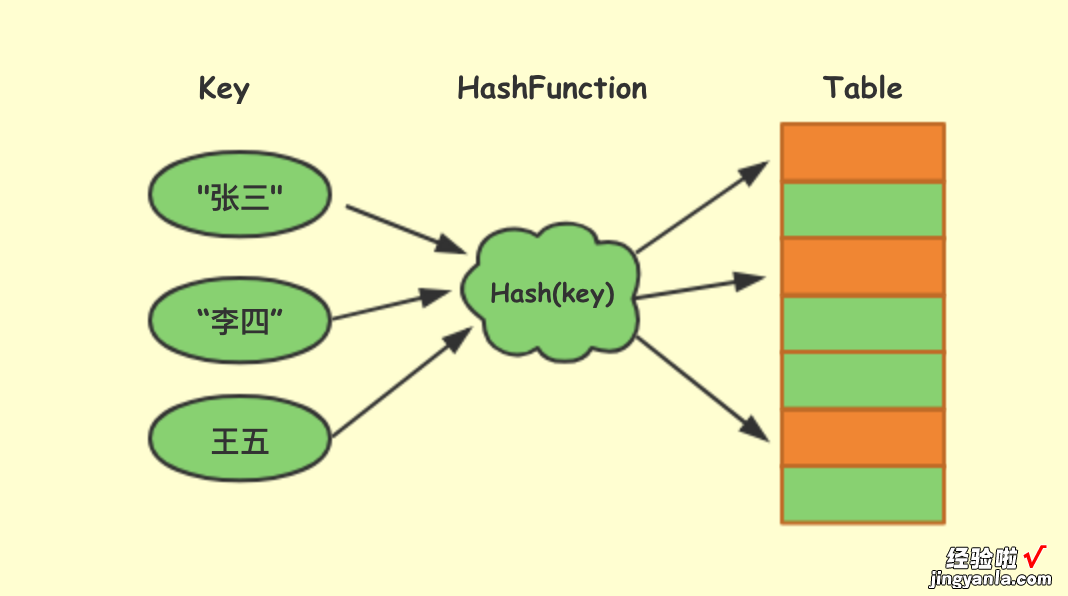
刚刚举的例子中,散列函数其实就是前台工作人员将名字和号码牌对应起来的一个对应关系,这个例子比较不恰当,并没有一个固定的公式 。那么,实用场景中,要怎么设计构造散列函数呢 , 我总结了三点基本的要求:
- 散列函数计算得到的散列值必须是一个非负整数;
- key1=key2,那hash(key1)=hash(key2);
- key1≠key2,那hash(key1)≠hash(key2);
第三点看起来合情合理,但是在真实场景中 , 要想找到一个不同的键得出的散列值都不一样的散列函数几乎是不可能的,即便像业界著名的MD5、SHA、CRC等哈希算法也无法避免散列冲突,因为数组的空间有限 , 函数计算得到的值还必须在数组个数范围内,因此就会有很大概率出现冲突 。
散列冲突
再好的散列函数也无法避免散列冲突,那怎么办呢?只能通过其他方式解决,一般散列冲突的解决办法有两类:开放寻址法和链表法 。1.开放寻址法
开放寻址法的核心思想是 , 如果出现了散列冲突,就寻找下一个空闲位置,插入新的数据 。开放寻址法也有多种方式,将介绍一个简单的探测方法,线性探测(Linear Probing) 。