应用场景
某员工收到包含几百页的pdf文件 , 这几百页pdf文件格式都是一样的 。员工需要获取其中的一个送货单编号 , 根据这个送货单号匹配送货项目,送货数量等等 , 且无法获取excel版本 。样本生成
为了不泄露公司机密,下面将使用百度公开的一个送货单模板生成pdf,来实现送货编号的获取 。假设要获取订单编号 , 且文件格式为pdf,测试版本共有4页,格式完全一样,但是编号不相同 。
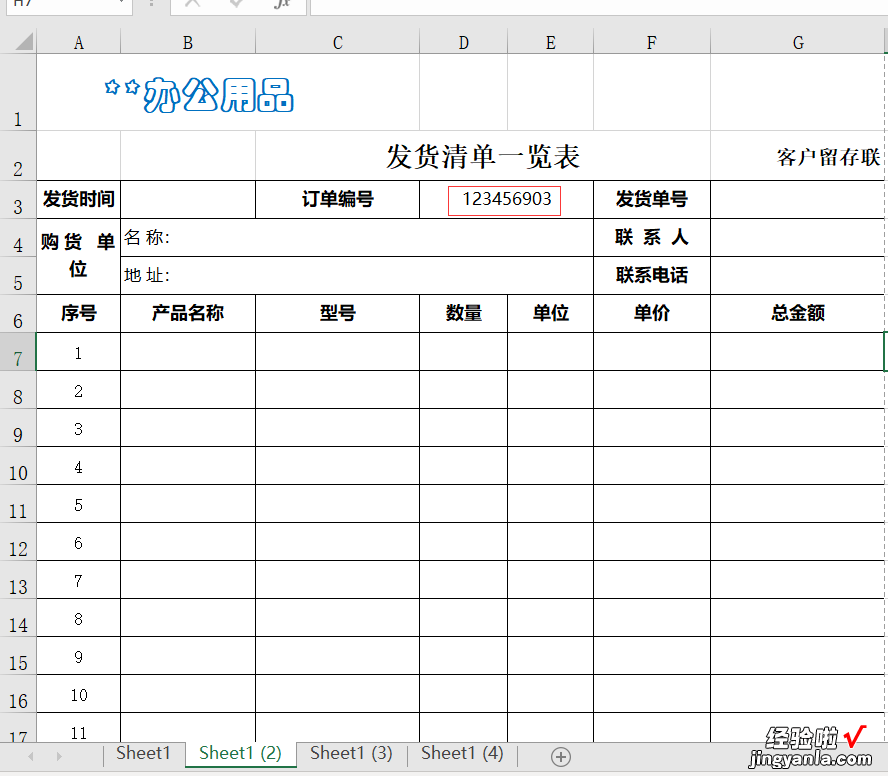
首先使用excel自带的pdf打印机生成pdf样本 。
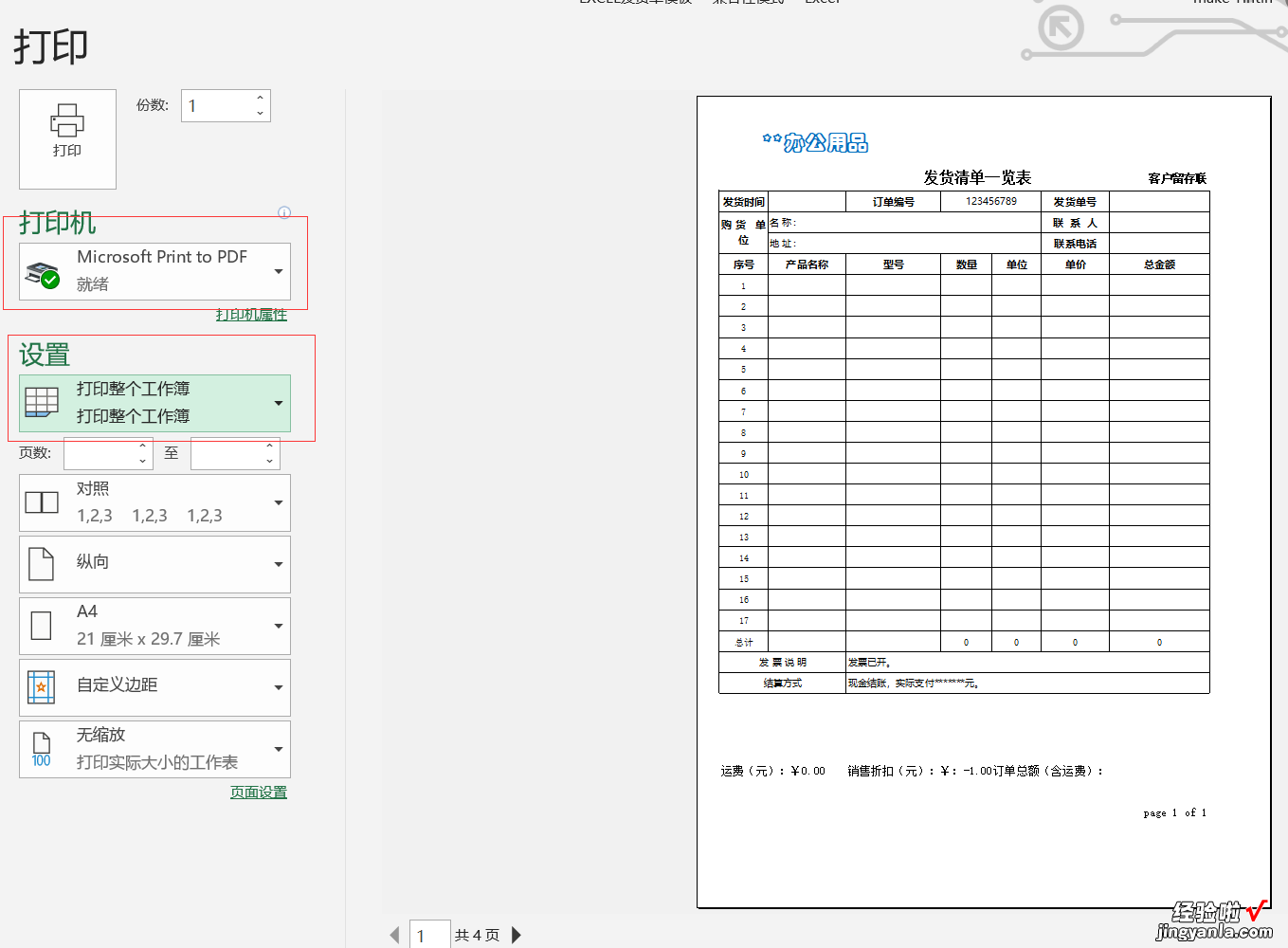
导出图片
- 打开pdf识别工具,选择文件,选择导出并切割
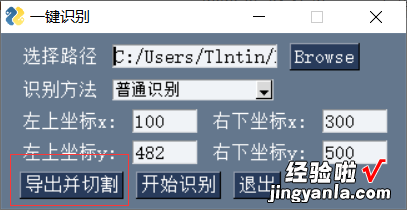
- 之后会生成一个“导出路径”文件夹 , 里面有导出的图片和切割的图片 。

- 打开切割后文件夹,发现并没有订单编号的图片,这是因为需要你手动获取切割位置 , 默认的切割位置是我帮女朋友做他们公司坑爹的pdf文件定位的 , 所以你在使用的时候需要手动定位
- 下面将使用网页版ps来获取切割位置
获取切割位置
- 打开网页版ps:https://www.uupoop.com/
- 上传刚刚导出的图片
- 使用矩形框工具,然后拉到“项目编号”所在单元格的左上角,记录一下长宽
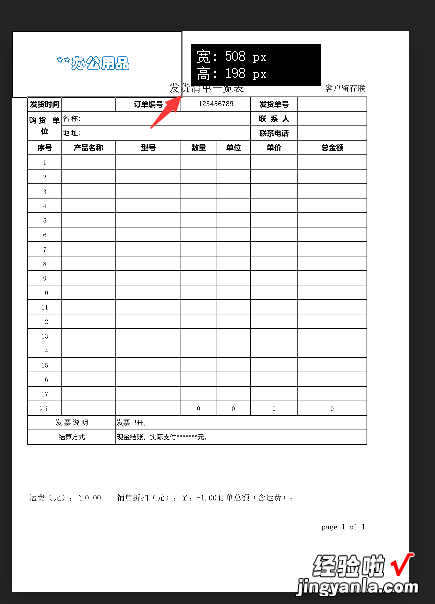
- 左上角的点 , 高508,宽198
- 然后测试“项目编号”右下角的点所在位置
- 右下角的点,长715,宽239 。记录下这两个坐标 。
再次切割
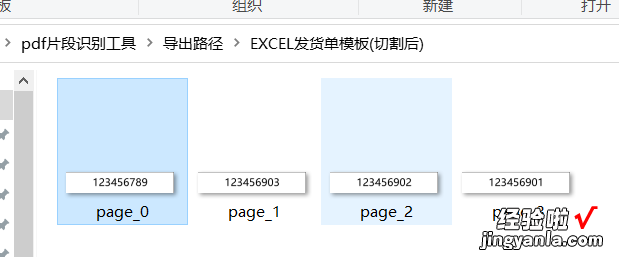
- 和之前一样 , 重新打开工具,填入点(508,198) , (715, 239)

- 查看切割效果,目测还不错,可以作为下面的识别材料了 。
获取百度AI文字识别api
- 搜索“百度AI开放平台”,点击控制台,注册登录
- 点击文字识别,选择创建应用,随便输入应用名和用途
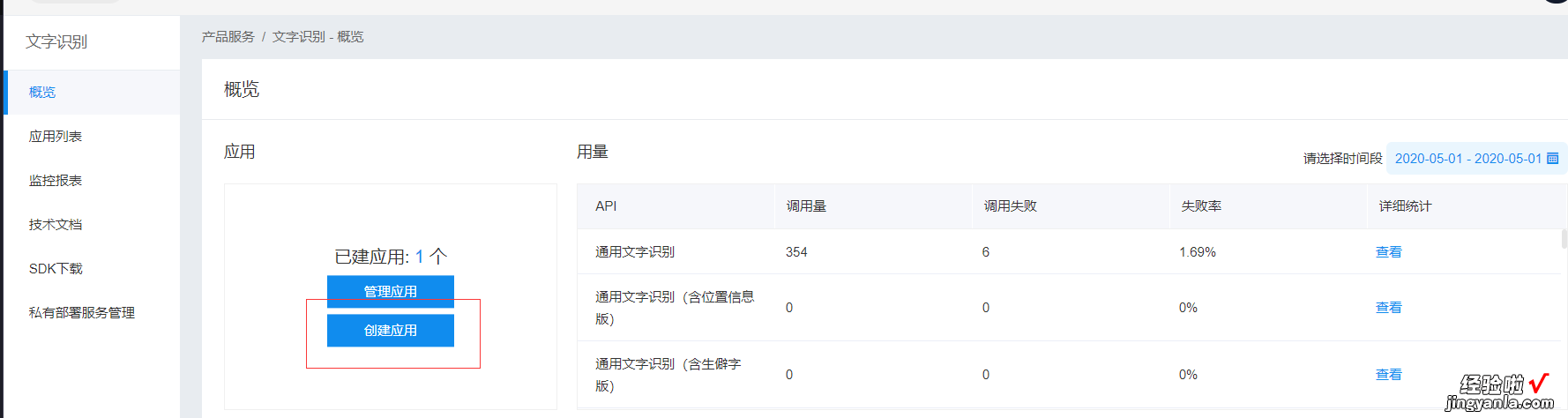
- 点击管理应用,记录你的api相关信息 。

- 填入pdf识别工具自动生成的api.json文件(可以右键,打开方式,记事本打开,推荐使用Notepad)
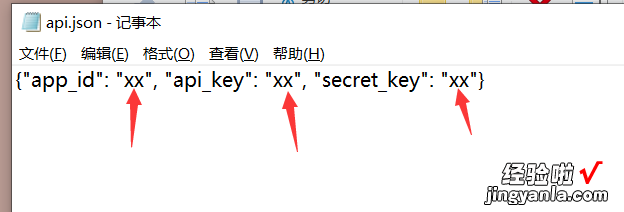
- 填写好后保存,准备工作完成 。
识别片段
- 点击“开始识别”即会自动识别刚刚切割生成的图片文件 。
- 可以选择“普通识别” , “普通识别高精度版”,“识别数字” , “识别票据”
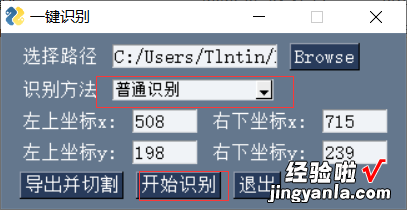
- 本次使用普通识别高精度版测试识别效果 。
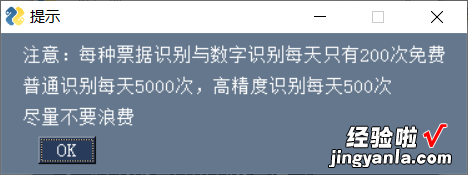
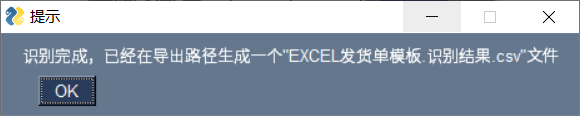
- 识别效果
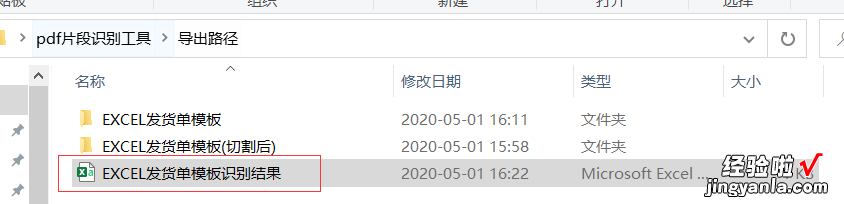
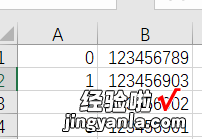
目前准确率100% , 没有出现错误 。
软件及模板分享
关注并私信“pdf片段识别”即可获取相关文件【pdf批量识别片段文字内容小工具】python源码开源地址:https://github.com/Tlntin/pdf_tools