我们每天都会接触到大量的信息,如何在短时间内高效地阅读并提炼信息是非常关键的 。目前通用的有chatpdf和askpdf等,但都需要魔法才能使用 。
本文将搭建我们自己的国内站,用的是langchain大模型 , 还集成了微信登录 微信支付 分销以及VIP会员功能,更适合国内使用,支持PC和移动端 。
功能介绍:它可以快速识别和分析PDF中的关键信息 , 帮助我们在短时间内把握文档的核心内容 。它的使用非常简单 。
首先打开网站,无需魔法就可以使用
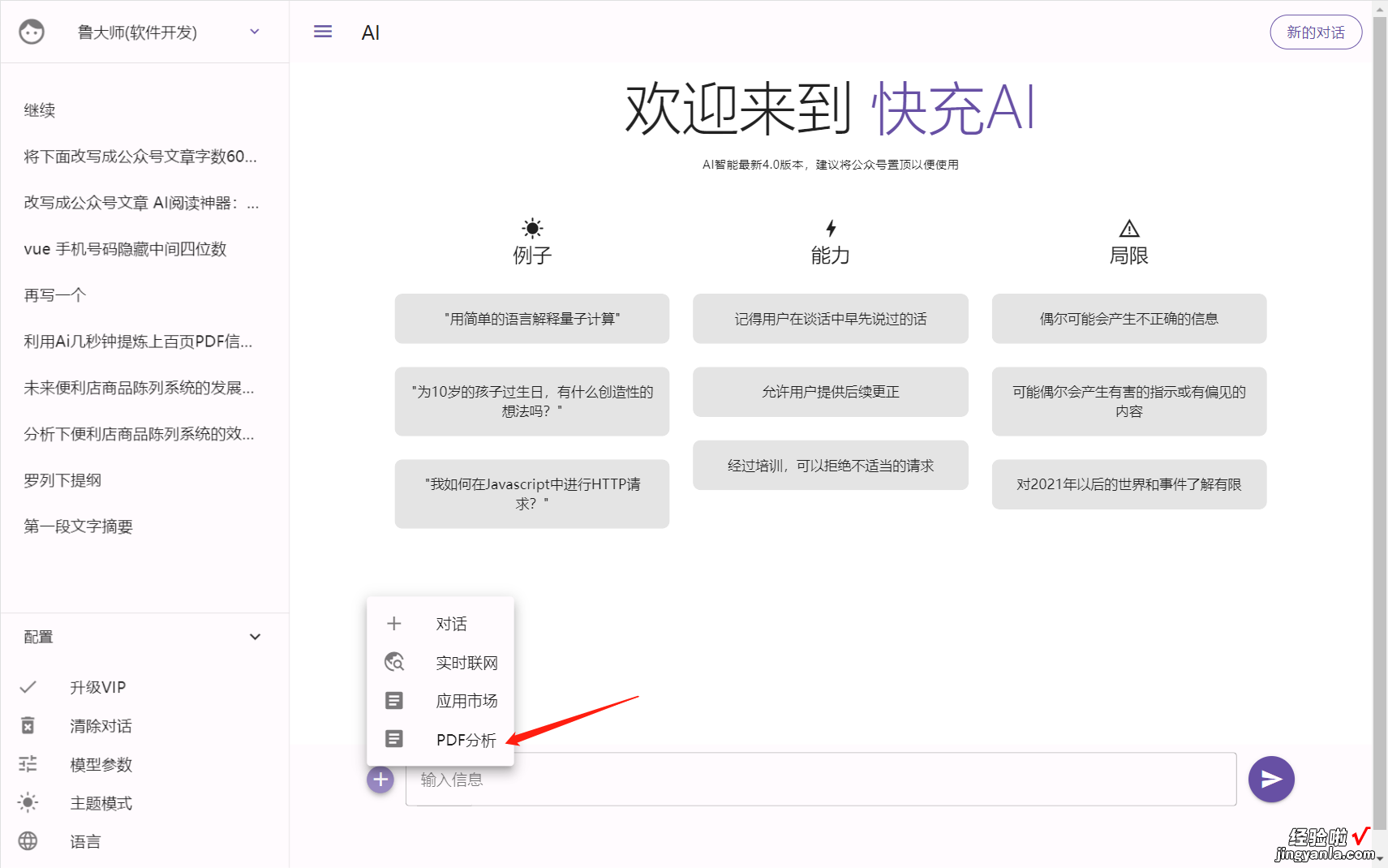
上传pdf
将本地的文档传输上去即可 。比如将这个PDF文档《连锁便利店商品陈列管理系统的设计策略》传上去,43页,只需要几秒钟,它就完成学习,并给出该文档的主要信息,以及列出3个我们可能会问它的问题 。
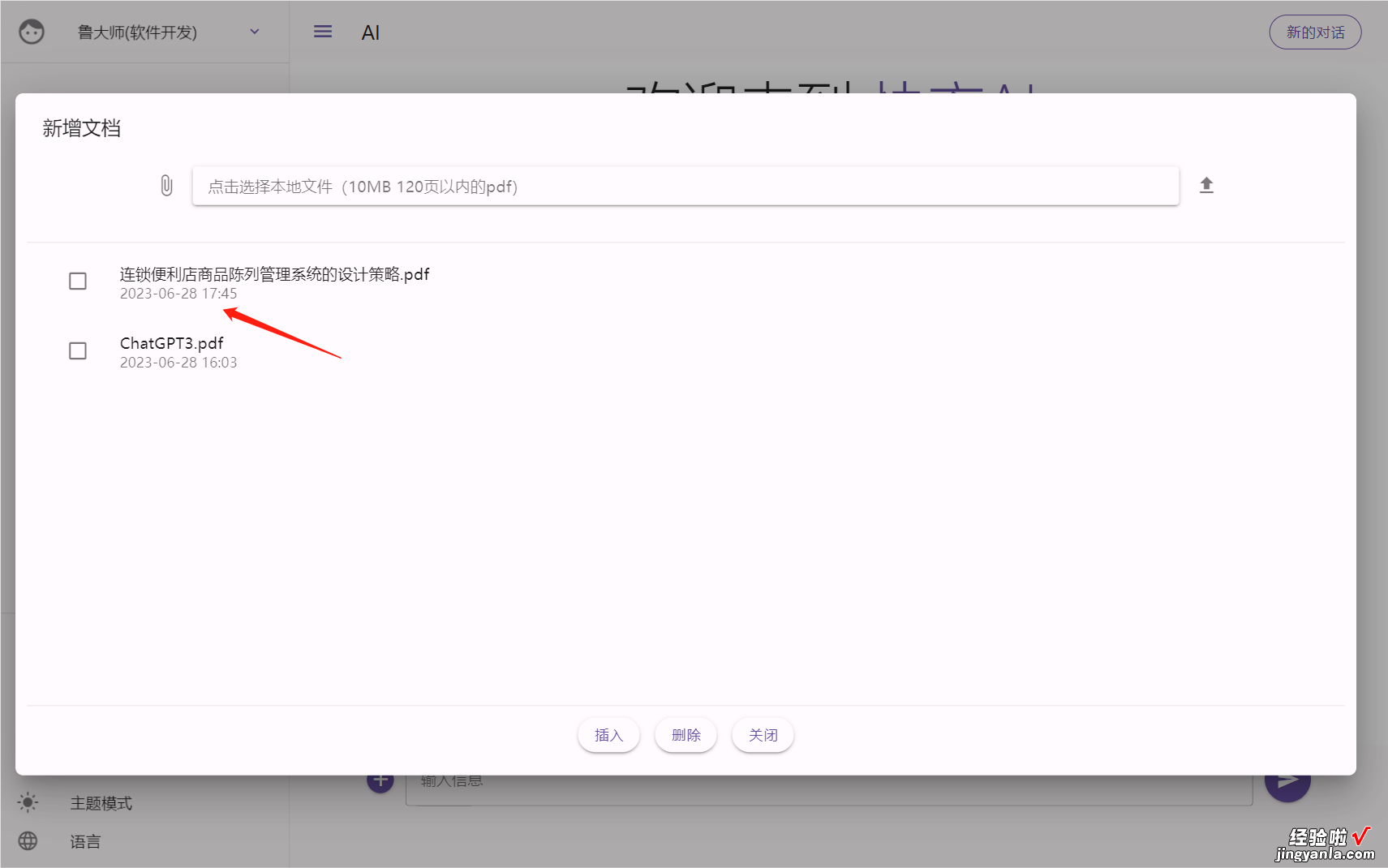
选择pdf文件
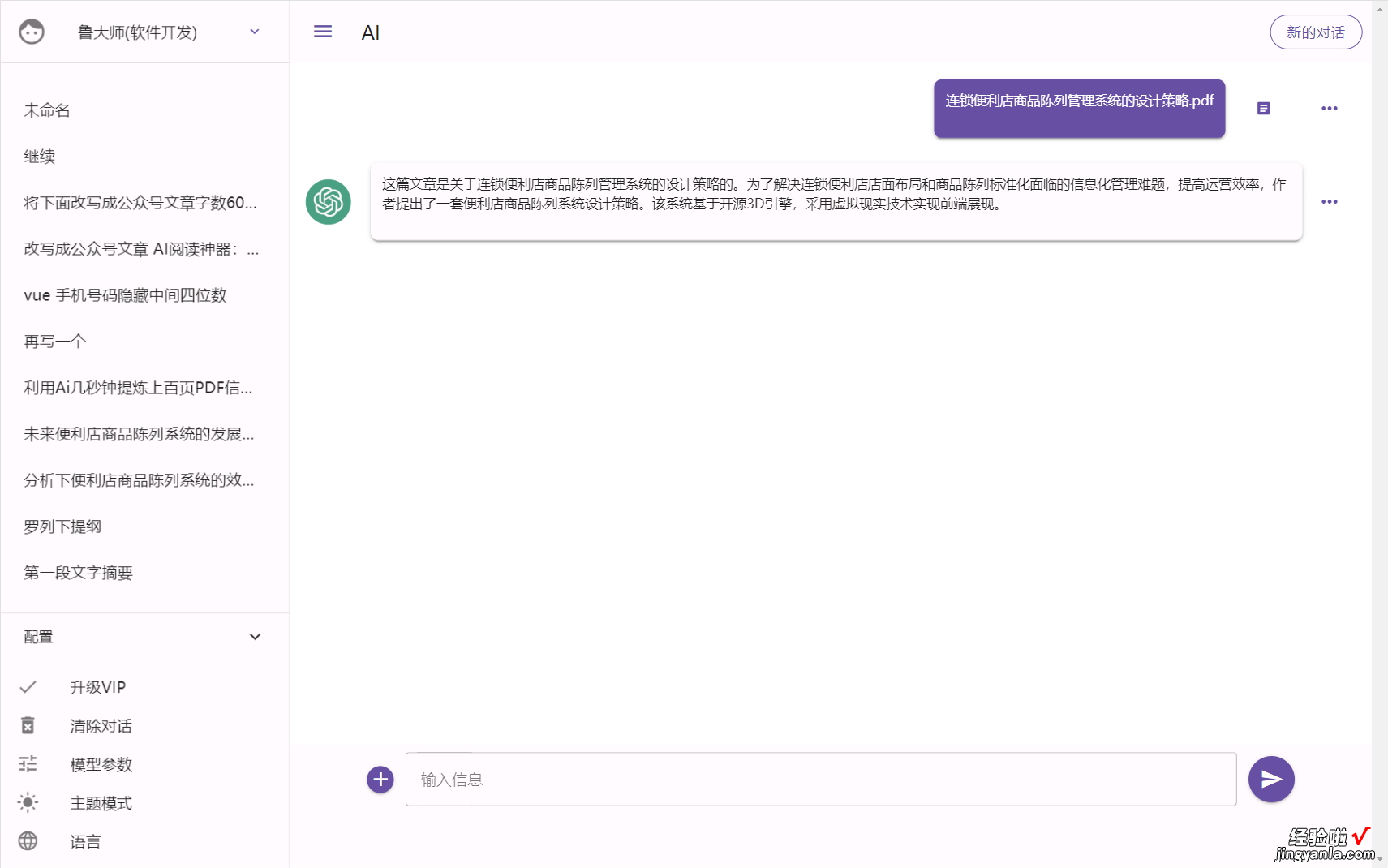
自动解析内容
这款神奇的工具有以下几个好处:
高效智能:可以自动提取文档中的关键词、概念和观点 , 帮助我们快速了解文档的核心内容 。
多语言支持:支持多种语言,无论您阅读的文档是中文、英文还是其他语言 , 都可以轻松应对 。
用户友好:具有简洁直观的用户界面,即使是初次使用的用户也能快速上手 。
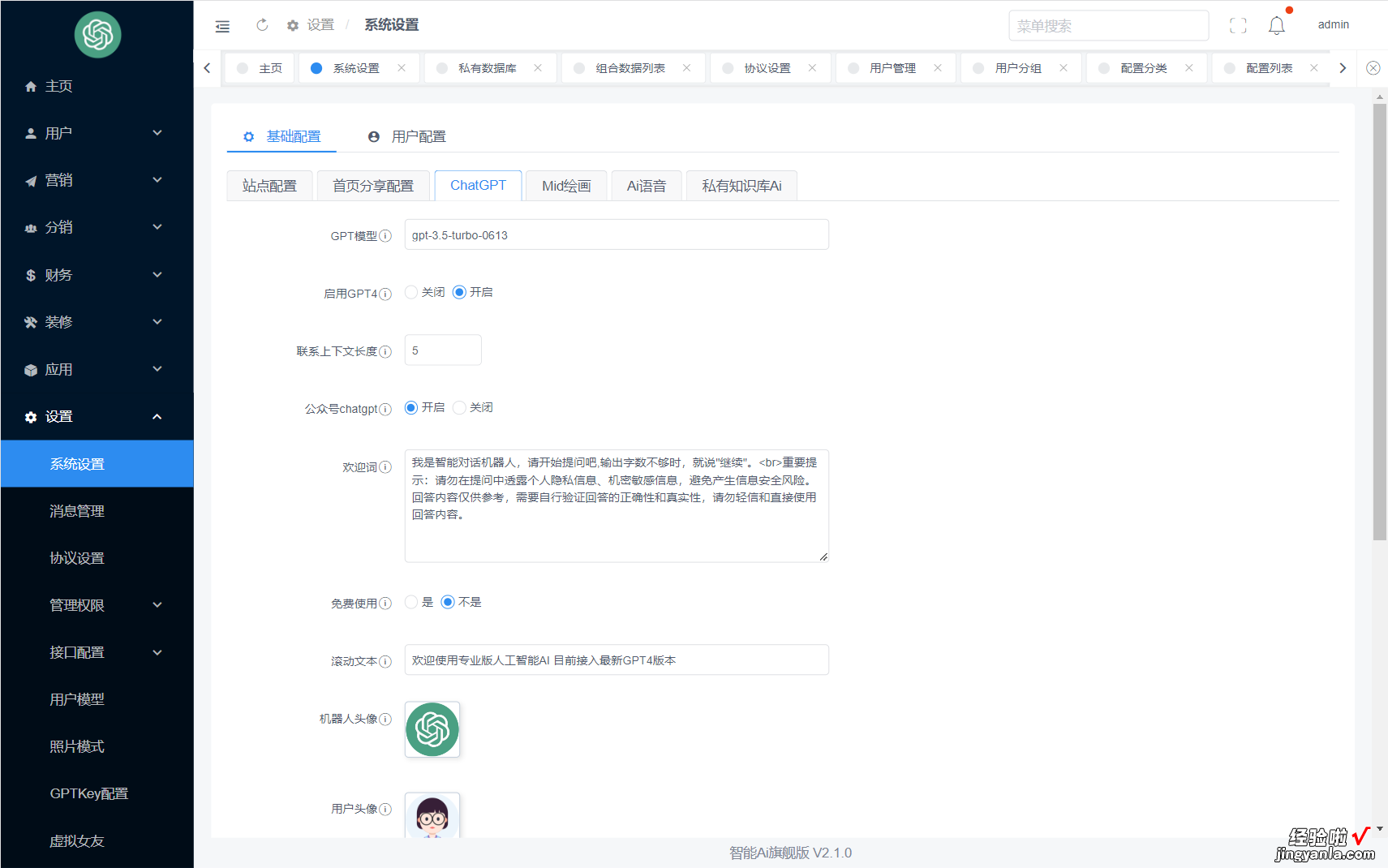
后台展示
具体实现流程(原理):
1、读取PDF文件:ChatPDF首先读取PDF文件,获取其中的文本内容 。可以使用现有的PDF处理库,如PyPDF2或PDFMiner等 。
2、文本清理和标准化:提取出来的文本需要进行清理和标准化处理,以便于后续处理 。例如 , 去除特殊字符、标点符号、空格等 。可以使用自然语言处理技术,如正则表达式、字符串操作等 。
3、分段和分句:将文本按照段落进行分段 , 然后再将每个段落按照句子进行分句 。这可以使用先进的文本处理库和语言模型来实现,如NLTK、spaCy等 。
4、转换为向量表示:使用OpenAI的Embeddings API将每个分段转换为向量表示 。该向量能够将文本的语义编码成数值形式,方便与问题的向量进行比较 。这可以通过调用Embeddings API的接口实现 。
5、问题匹配:当用户输入问题时,ChatPDF使用Embeddings API将问题转换为一个向量表示 。然后,将该向量与每个分段的向量进行比较,以找到与问题最相似的分段 。可以使用常见的相似度计算方法 , 如余弦相似度等 。
6、Prompt聊天:找到最相似的分段后,作为prompt传递给ChatGPT模型,通过调用OpenAI的Completion API , 让ChatGPT学习并生成回答 。
7、最后利用Embeddings API让ChatGPT学习特定的知识,并能够根据学习到的知识回答用户的问题 。可以应用于健康咨询、法律咨询、技术支持、学术研究等领域,将相关资料转换为向量进行学习,以便ChatGPT能够回答相关问题 。
【利用Ai秒懂上百页PDF,轻松掌握核心内容 搭建私有ChatPDF】结束语:利用现有技术,实现各类功能,解决工作问题,是我们开发的目的 , 稳定可靠,有团队维护,需要搭建的同学可以私信博主 。