在上一篇文章里,我们探讨了银行内部的两种数据人:
技术数据人和业务数据人 , 他们的角色、职责和痛点,今天我们继续探讨一下 , 这种现象出现的原因以及我们能做些什么 。
在银行,业务与科技的矛盾由来已久,业务抱怨科技开发慢,质量差,体验不好,科技抱怨业务老改需求,自己需求都没想清楚 。
到了数据这里,不过是业务与科技矛盾的延伸与加剧,延伸是因为数据也归属科技条线,加剧则是因为数据产生及提取加工的过程比科技开发更加滞后 。
我们看下图:
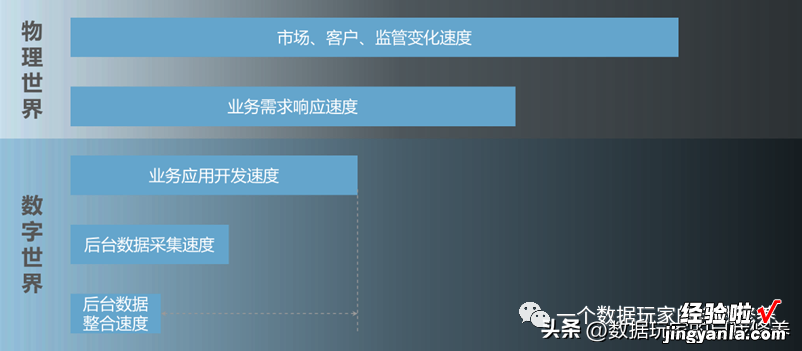
在物理世界里,市场、客户、监管的变化速度是非常快的 。
能通过数据提取解决的需求,自然是通过数据提取来解决,通常也是为了应对市场、客户或监管发生的变化,从上图大家也可以看出,相比物理世界的变化 , 数字世界的变化肯定是延迟的 , 因此才需要尽量在每个环节缩短时间,以应对物理世界的变化 。
对于数据提取解决不了的需求,物理世界发生变化以后,业务部门需要理解现状,并把这些变化转化为业务需求,这个过程也充满挑战 。需要对监管意图了解,对同业现状熟悉,对本行系统更是如数家珍 。
然后科技部门需要把业务需求转化为技术开发需求,完成各种评审、立项流程后才能启动开发 。
这个过程,快则数日至数周 , 慢则数月 。
实际开发的过程并不长 , 但是还有测试的过程,包括内部测试、SIT、UAT、准生产测试等等,测试完成后根据投产窗口定期上线 。
国有银行一年通常有4个大版本日,4-8个小版本日,股份制和城商行最快的也需要一月一个投产日,领先的互联网银行可以做到每周一版本(也仅限非核心系统) , 接近互联网公司的迭代速度 。
上线以后系统可以完成业务需求,但是数据的积累,以及积累以后的采集还需要一段时间 , 而且很多时候,仅采集一个系统的数据是不够的,需要整合其他系统的数据,加工后一并采集 。
这就涉及到数据仓库和数据集市,数据入仓(加载进入数据仓库)又需要一段时间 。
这一系列流程结束之后 , 才可以进入到上文提到的数据提取流程 。
因此,不是业务部门着急,而是市场变化、业务需求、系统开发、数据采集天然的存在巨大的时间差 , 业务考核的压力大,不得不在每一个环节压缩时间 。
听起来,这似乎是一个无解的问题 , 实际上还是有很多改进的地方 。
- 比如提需求时,可以更加的有预见性,通过对过去和当前情况的研判 , 预测下一步市场、用户、监管可能发生的变化,提出具有前瞻性的需求;
- 比如在开发时,通过敏捷开发的方式,小步快跑 , 快速迭代 , 采用先做出基础产品用起来,再根据反馈逐步完善的模式,可以弥补开发滞后的时间差;
- 比如在数据采集阶段,采用流数据采集和计算的模式,让数据产生后能够实时的被采集和计算;
- 比如在数据整合及提取阶段,通过数据中台等领先架构,整合全行数据,并预加工指标,让业务可以直接探索数据 , 极大的缩短用数流程 。
让技术人学业务这件事情,非常依赖于组织架构和考核的调整 。
不管是学业务还是学技术 , 核心的环节在于下场实操 。如果光学不练,不下场真正的做业务或者使用技术,是无法找到感觉的 , 也无法真正理解对方 。
要让技术数据人真正的有做业务的感觉,必须让他待在业务部门,每天和业务一起开会,讨论经营目标 , 解决业务问题,急业务之所急,痛业务之所痛 。数据不准一起挨骂 , 数据提取太慢一起着急,最好还背上一半的业务KPI 。
因此,组织架构、考核机制不调整 , 技术数据人学业务这件事情还是挺难落地的 。而业务数据人学技术这件事,倒不必调整组织架构或考核机制,只要自己真的学了,并且在日常工作中用了 , 就能实实在在的提升工作效率 。
真正的难点,在于心态的调整 。
建议业务数据人不必排斥技术,或者给自己设限 。我接触过很多业务部门的同事 , 一听到技术专业术语就谈虎色变:
“不要跟我讲技术,我听不懂”能进银行,大家的智商都不低 , 都是本科研究生学历,大行甚至都是985/211 , 要想学点新东西根本不难,但是大家还是习惯待在自己的舒适圈里 。
“哎呀,我学不会的,还有好多事情,不浪费时间了”
“这高大上的,我小白不理解”
你不出圈 , 我不出圈,机构怎么出圈,怎么转型?
稍微学点技术 , 能让日常工作事半功倍,省下更多的时间可以干更重要和紧迫的事,何乐而不为?
学习技术并不意味着一定要编程,可以先从使用工具开始 。
版本管理工具:SVN
这可以说是最易上手的版本管理工具了 。为什么要用版本管理工具呢?
【银行数据人生存现状——问题如何产生,以及如何做出改变】主要是在多人协作的场景下,如果几个人同时需要修改一个文档,原有方式通常是A改完发B,B改完发C,如果有人基于历史版本做了改动,那么有些改动就会丢失 , 比如C在B改完之前,就开始基于A的版本修改了 , 那B修改的内容就会丢失,如果B又没有采用审阅模式等可以追溯修改位置的功能 , 则只能通过两个版本的文件比对来查找,效率极其低下,而且很容易出错 。
如果采用版本管理工具,类似问题完全可以避免 。
SVN在修改文件时,可以先锁定文件,如果想修改文件时发现已经被锁定 , 说明别人正在修改,可以等对方提交修改以后,再更新最新版本的文件,然后锁定、修改 。
所有的最新版本文件都存放在版本管理服务器上 。万一本地文件丢失也没关系,而且最关键的,可以方便的追溯历史上的每一个版本,如果在提交时加上注释,还可以清楚的知道每一次因为什么原因 , 修改了哪些内容 。
学会SVN的常用操作大概只需要5-10分钟,一杯下午茶的时间都用不了 , 强烈业务数据人,乃至于所有的非技术岗位尝试一下 。
数据库:Access
一般安装了Office套件都会安装Access,在支持编写SQL脚本进行查询的同时,Access也提供了功能强大的图形界面,可以通过图形界面的操作实现与SQL脚本等效的功能 , 而且可以直接导入Excel等常用数据源 。
为什么要使用Access代替Excel呢?
不可否认,Excel功能非常强大,在日常工作中,没有Excel做不到的,只有你想不到的 。
但是,Excel在处理超过十万行数据的时候,特别是涉及列之间通过公式加工计算等等操作时,由于全部需要加载到内存进行计算 , 会导致内存、CPU等资源迅速耗尽,从而使得完成基础的操作都非常卡顿 , 甚至经常出现Excel程序崩溃的情况,这简直是数据人的噩梦 。
而Access , 虽然是一个相当轻量级的数据库,但是由于底层实现方式的不同,在处理大量数据时更加游刃有余,最关键的是学习成本低 , 通过图形界面的操作即可完成常用操作 。
不敢说救表哥表姐于水火之中,至少能极大的减轻日常工作量 。
可视化的数据分析工具
既然被称作数据人 , 那就离不开数据分析 。
虽然大部分场景,使用Excel就可以满足要求,但是仍然有一些场景,需要建立一些简单的模型 。
做个回归分析,预测一些趋势,给出一些基于数据分析的可靠结论,可以让你的报告更加有说服力 , 让领导对你的能力也更加认可 。
目前有不少工具,可以通过可视化的方式完成建模 , 一行代码也不用写 。
比如之前在开源还是闭源?从SAS与Python说开去中提到的WPS (据说现在已经更名为Altair SCL) :
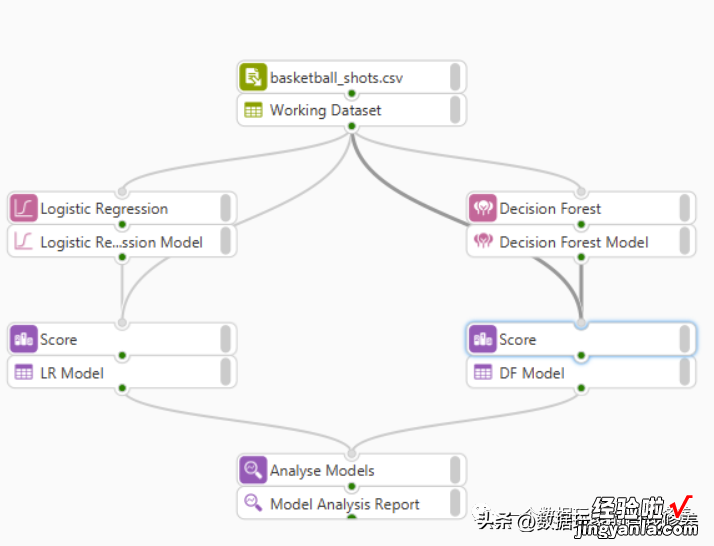
通过拖拉拽的方式,把数据源、模型结果组装在一起,就能自动完成建模和输出的过程 。这里放一个介绍视频,感兴趣的可以看看,核心特点是支持SAS, SQL,Python,R等语言来构建模型,可以混合多语言编程 。
上面提到的是支持SAS的开源和闭源的数据分析工具,现在主流数据分析市场上还有很多人喜欢用Python , 但对业务数据人来说,要在Jupyter Notebook上写python进行建模是有一定门槛的 。
现在市场上也出现了不少零代码数据建模工具 , 比如Knowledge Studio等产品,不需要编写代码就可以建模,还支持完全自动建模,这就对业务数据人非常友好,只需要稍微学点数据分析的基础原理就可以自主进行算法模型的构建;
对于技术数据人来说 , 这类零代码的建模工具也可以大大提升建模的效率,更具有意义的事是有了此类零代码工具 , 自己也能有更多的时间抽出来进行业务的研究,提升自身业务的能力,更有利于长远的职业生涯发展 。
结语
总的来看,受制于银行的组织架构和体制机制,业务数据人和技术数据人都面对着理想和现实的落差,一边憧憬着高大上的机器学习模型,一边苦哈哈的干着最基础的脏活累活 。
整个机构的现状很难改变,不妨先从自己开始改变,技多不压身,当你的视角发生变化以后 , 一切都会慢慢的变得不同 。