本文摘要
数据清理是耗时的,但是是数据分析过程中最重要和最有价值的部分 。没有清理数据,数据分析过程是不完整的 。但是如果我们跳过这一步会发生什么呢?
假设我们的价格数据中有一些错误的数据 。不正确的数据在我们的数据集中形成异常值 。我们的机器学习模型假设这部分数据集(也许特斯拉的价格确实在一天之内从50美元跳到了500美元) 。你现在知道分析的最终结果了吧 。
机器学习模型给出了错误的结果,没有人希望这样!由于预测的方式是错误的,你必须从头开始分析,再一次!因此,数据清理是分析的一个重要部分 , 不应该被忽略 。
文章目录
这个博客将带你通过整个过程的数据清理,并提供解决方案的一些挑战面临这个过程 。- 什么是数据?
- 各种数据来源
- 原始数据和处理过的数据是什么样子的?
- 数据清理的好处
- 高质量数据的特点
- 数据清理术语
- 清理数据的步骤
- 理解你的数据
- 数据清理中需要解决的基本问题
- 交易数据清理
- 已经存在的软件
- 学习数据清理的资源
- 常见问题
什么是数据?
数据科学是当今最受追捧的职业之一 。那么让我从回答这个古老的问题开始——什么是数据?根据维基百科,“数据是关于一个或多个人或物体的定性或定量变量的价值集合,通过观察收集 。” 。考虑一个包含不同种类水果运输信息的数据集 。

数据集中的一些变量可能是定性的,例如水果的名称、颜色、目的地和起源国、顾客的反馈(失望、内容、满意)或定量的,例如水果的成本、运输成本、装运重量、装运成本和装运水果的数量 。
其中一些变量可能来自其他较低层次的变量 。在这个例子中,运输成本来源于水果和运输成本变量的成本 。
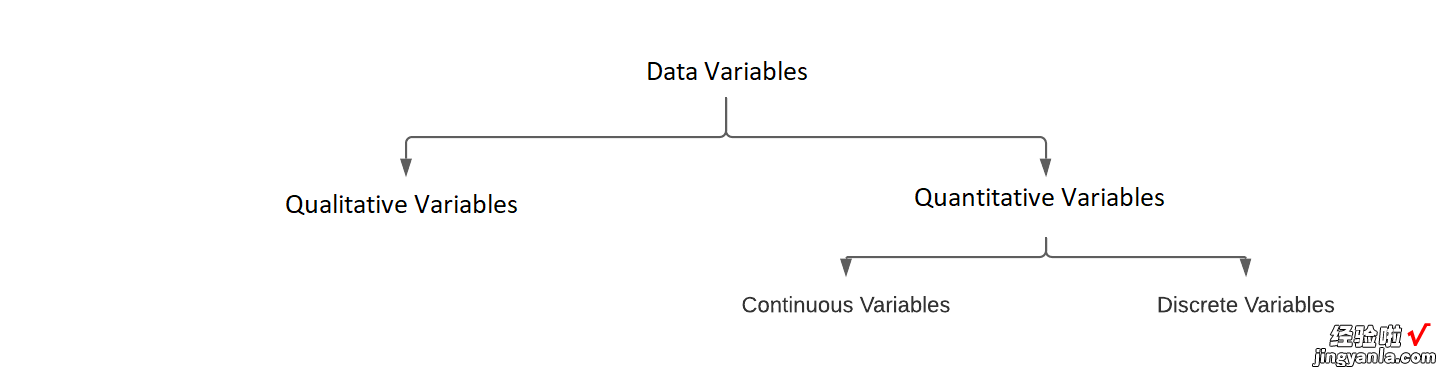
这些定量变量也可分为连续和离散两类 。顾名思义,连续变量在数行上是连续的,可以假定任何实值 。离散变量可能只有特定的值,通常是整数 。货物的重量将是一个连续的变量,而如果我计算每一批水果的数量,它将是一个离散的变量 。
定性变量可以分为名义变量和序数变量 。名义变量或无序变量是一种标签变量,这些标签没有定量值 。例如,水果的颜色或货物的目的地可能是名义上的变量 。序数变量或有序变量是那些标签具有定量值的变量 , 即它们的排序问题 。在水果的数据库中,客户反馈将是一个有序的变量 。
大多数人认为数据科学是传递非常准确和精确信息的漂亮的图表和图表 。然而,大多数人没有意识到生成这些数字的过程是必要的 。
数据分析流水线由5个步骤组成 。
原始数据-> 处理脚本-> 整理数据-> 数据分析-> 数据通信
通常,管道的前三个步骤被忽略了 。初学者直接跳到数据分析步骤 。任何公司或学术研究都将致力于获取他们的数据并在内部进行预处理 。因此 , 你会想知道如何获取原始数据 , 清洁和预处理它自己 。
这个博客将涵盖所有关于清洁和获取数据进行分析的内容 。
各种数据来源
首先,让我们讨论从哪里可以获得数据的各种来源 。最常见的来源可能包括来自数据提供网站的表格和电子表格,如 Kaggle 或加州大学欧文分校机器学习知识库或原始 JSON 和文本文件获得刮网络或使用 API 。那个 。Xls 或 。来自 Kaggle 的 csv 文件可能会被预先处理,但原来的 JSON 和 。需要处理 txt 文件以获得某种可读格式的信息 。详细的数据提取方法可以在这里找到 。原始数据和处理过的数据是什么样子的?
理想情况下,您希望您的干净数据是这样的: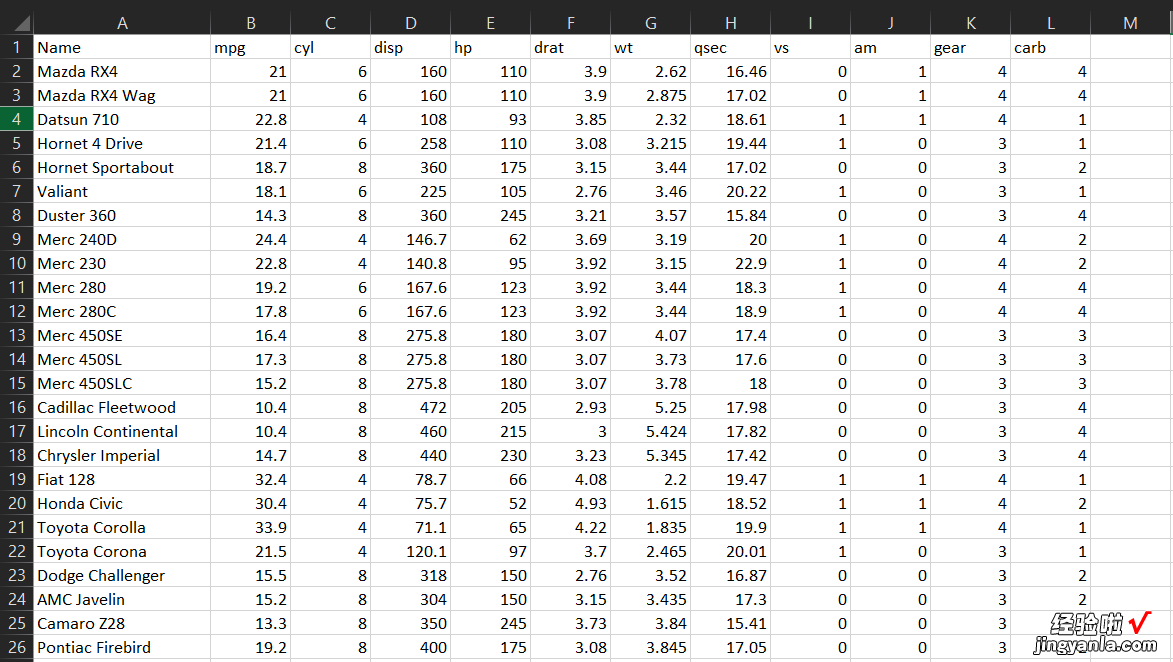
每列只有一个变量 。在每一行中 , 您只有一个观察结果 。它被巧妙地组织成一个矩阵形式,可以很容易地在 Python 或 R 中导入,以执行复杂的分析 。但通常情况下,原始数据不是这样的 。它看起来像这样:

数据多的让人头皮发麻...
这是使用 Twitter API 传递查询的结果,以获得乔?拜登(Joe Biden)过去的20条推文 。您还不能对这些数据执行任何形式的分析 。
稍后我们将详细讨论原始和整洁数据的组件 。
数据清理的好处

如上所述,一个干净的数据集对于产生合理的结果是必要的 。即使希望在数据集上构建模型,检查和清理数据也可以指数级地提高结果 。向模型输入不必要或错误的数据会降低模型的准确性 。一个更清晰的数据集会给你一个比任何花哨的模型更好的分数 。一个干净的数据集还将使您组织中的其他人将来更容易处理它 。
高质量数据的特点
在执行数据清理之后,您至少应该具有以下这些东西:- 你的原始数据
- 干净的数据集
- 描述数据集中所有变量的代码本
- 一个指令表,包含对原始数据执行的所有步骤,这些步骤产生了干净的数据
- 没有软件应用到它,因为它已经交给它
- 没有对数据执行任何操作 。
- 未执行摘要
- 未从数据集中移除任何数据点
- 每一行应该只有一个观察
- 每列应该只有一个变量
- 如果数据存储在多个表中,请确保这些表之间至少有一列是通用的 。这将帮助您在需要时一次从多个表中提取信息 。
- 在每个列的顶部添加一行,其中包含变量的名称 。
- 尽量使变量名易于阅读 。例如,使用 Project _ status 而不是 pro _ stat
- 处理过程中使用的所有步骤都应记录下来,以便从一开始就可以重现整个过程
- 关于变量及其单位的信息 。例如,如果数据集包含一个公司的收入,一定要提到它是以百万还是以十亿计的货币 。
- 关于总结方法的信息 。例如,如果年收入是变量之一,请提及你用什么方法得出这个数字,是收入的平均值还是中值 。
- 提及你的数据来源,无论是你自己通过调查收集的还是从网上获得的 。这样的话,也提一下网站 。
- 一种常见的格式是. doc、 . txt 或标记文件(. md) 。
- 电脑脚本
- 这个脚本的输入应该是原始数据文件
- 输出应该是经过处理的数据
- 脚本中不应该有用户控制的参数
数据清理术语
- 聚合:使用多个观察值来提供某种形式的变量的摘要 。常用的聚合函数有 。总额() , 。平均()等 。Python 提供了 。可以同时执行多个函数的聚合()函数 。
- Append:Append暗示垂直连接或堆栈两个或多个数据框架、列表、系列等 。使用函数追加数据框架 。
- 插补:一般统计学家将插补定义为填补缺失值的过程 。我们将在后面的博客中更详细地讨论插补 。
- Deduping:Deduping 是从数据集中删除重复观察值的过程 。本博客稍后将对此进行更详细的讨论 。
- 合并:合并和附加是数据清理中最令人困惑的术语 。合并两个数据框架还包括将它们连接在一起 。这里唯一的区别是我们横向连接它们 。例如 , 如果我们有两个数据集 , 一个包含用户的 Facebook 数据 , 另一个包含用户的 Instagram 数据 。我们可以根据用户使用的 email id (两个数据集中的公共列)合并这两个数据集 , 因为这对某个用户来说很可能是公共的 。
- 缩放:缩放或标准化是缩小一个特性的范围并使其介于0和1之间的过程 。这是用来准备的数据 , 以建立一个机器学习模型上 。机器学习算法算法给高值赋予较高的权重 , 给低值赋予较低的权重 。缩放将处理这种值的高度变化 。
- 解析:是将数据从一种形式转换为另一种形式的过程 。在博客的前面,我们研究了来自 Twitter API 的原始数据 。这些数据的原始形式是没有用的,所以我们需要解析它 。我们可以将每条 tweet 作为一个观察值,将 tweet 的每个特性作为一个专栏 。这将使数据以表格的形式显示和可读 。
清理数据的步骤
有几个步骤,如果遵循得当,将确保一个干净的数据集 。- 好好看看你的数据,了解其中发生的基本问题
- 列出所有的基本问题并分析每一个问题 。尽量估计问题的根源
- 清理数据集并再次执行探索性分析
- 检查清洁后的问题
理解你的数据
接收数据时要执行的第一个步骤之一是了解所收到的数据 。了解数据集包含什么——其中的变量、它们的类型、缺失值的数量等等 。在本博客中,我们将使用银行的合成客户交易数据 。这里提供数据集 。首先,读取 excel 文件并使用. head ()和. info ()方法获取数据框架的摘要 。
import pandas as pdimport numpy as npdf=pd.read_excel('ANZ_synthesised_transaction_dataset.xlsx')df.head().head()方法将向您展示前5行

Info ()
Info ()方法将提供 DataFrame 的简明摘要 。

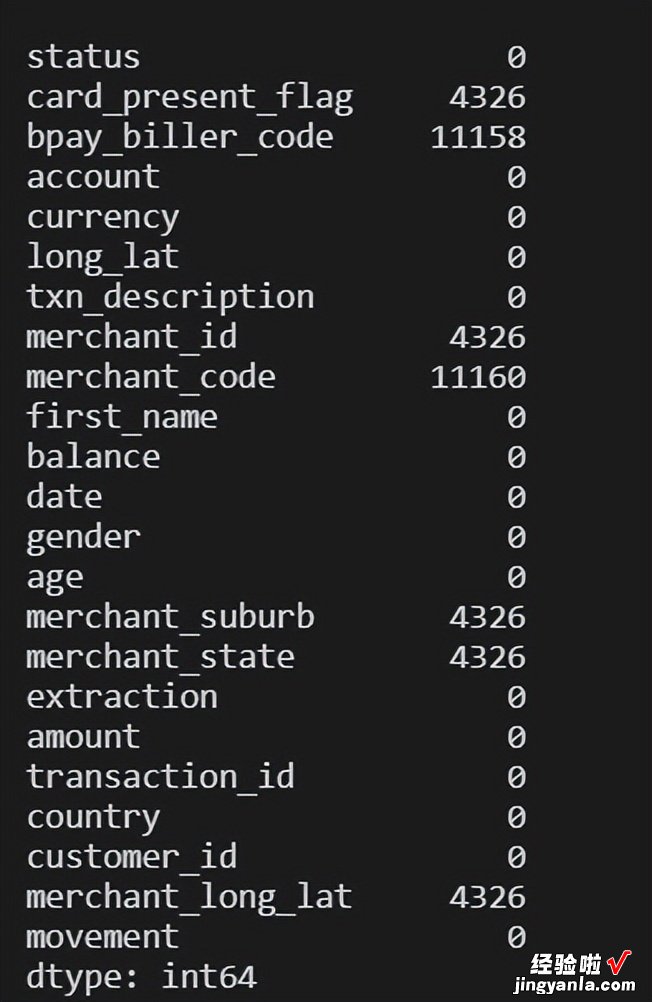
您将得到类似于下面这样的输出 。这将显示列名、每个列中非空值的数量以及每个列的数据类型 。
尽管这会间接显示每列中的空值,但您还可以使用 。是的 。Sum ()获取每列中的空观察值数 。
. isna ()将返回一个布尔数组 。如果观察值为空,则返回1; 如果观察值不为空,则返回0 。
() . sum ()
您还可以使用. only ()在特定列中找到唯一值
为了观察移动列中的唯一值 , 我们使用-
Movement.only ()

这些步骤应该让您对必须对数据进行哪些清理有一个基本的了解 。
数据清理中需要解决的基本问题
在原始数据中看到的一些基本问题是:缺失值处理
有时在数据集中 , 您会遇到丢失或为空的值 。这些缺失的值可能会影响机器学习模型,并导致它给出错误的结果 。因此,我们需要适当地处理这些缺失的值 。这个问题可以通过多种方式解决:- 处理这个问题最简单的方法就是忽略缺少值的观测值 。这是可行的,只有当缺失的观察弥补了整个数据集的一小部分 。忽略大量的观察结果可能会缩短数据库并得出错误的结果 。这可以通过使用 df.drona ()方法实现 。
- 另一种方法是估算缺失的值 。这意味着您可以确定哪个值可能是丢失的值 。这可以通过取变量的平均值/中值或找到类似的观察值并相应地计算缺失值来完成 。只有在正态分布的情况下才应该使用均值,也就是说 , 数据没有倾斜 。在数据有偏差的情况下,应使用中位数 。这可以通过使用 df.filna ()方法来完成 。
- 有时缺少的值本身可能表示某些数据 。例如,有些人可能不愿意与任何性别保持一致 。这些观察结果不能被归类为缺失 。在这种情况下,最好的办法就是让这些观察结果保持原样 。
重复的价值观
数据集中可能有重复的值 。这可能是由于收集数据时的人为错误造成的 , 也可能是在合并来自不同来源的数据集时发生的 。处理它的最佳方法是删除重复的值 。这可以通过使用 df.drop _ double ()方法来完成 。离群值

离群值是指对于列来说异常大或小的值 。它们与平均值的偏差远远大于变量的标准差 。然而 , “大得多和小得多”这样的术语是非常模糊的,并没有提供一个普遍的价值来考虑一个观察作为一个离群值 。
一般来说 , 如果一个值超过1.5 * IQR,那么它就是一个异常值 。IQR 表示四分位间距 。
例如,如果 IQR 为100,Q1和 Q3值分别为50和150 。因此,如果观测值低于 Q1-1.5 * IQR,即低于50-1.5 * 100 = -100 , 那么观测值就是异常值 。高于 Q31.5 * IQR 的值也是异常值 。
一些机器学习模型,比如回归 , 容易受到异常值的影响 。因此,它们应该被删除 , 但只有在彻底审查了异常值的原因之后 。
字符串清理
字符串变量中可能出现不规则现象 。这些情况可能是由于人为错误或从不同来源收集数据时发生的 。它们涵盖的范围很广,可能因数据的不同而有所不同 。解决这个问题的方法也因用户而异 。这通常取决于问题本身 。最常见的错误是拼写错误和不同格式的书写相同的意见 。拼写错误很难解决 。如果它们的数量很少 , 可以通过搜索观察结果手动完成 。如果拼写错误引起大问题 , 可以通过使用模糊匹配来找到它们 。第二个问题可以通过在 python 中使用 regex 库来解决 。它使用部分匹配来查找和替换 。它还可用于标准化,以删除特殊字符,并在字符串中只保留字母数字字符 。比如说,
import regex as re
x='abc[#4 6a}'
x=re.sub(r"[^a-zA-Z0-9s]","",x)
x
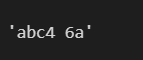
这里我们可以看到这个表达式 re.sub (r“[ ^ a-zA-Z0-9 s ]”,“” , x)删除了所有不是字母数字或空格的字符 。因此我们可以使用 regex 来执行模式匹配 。
标准化
数据的标准化意味着将所有的观测结果放在同一类型的一个变量中 。对于一个数值变量,确保所有的观测值具有相同的单位 。一定要在栏名或代码本中提到度量单位 。字符串变量必须都是大写或小写,因为这使得它们在任何时候都更容易搜索 。
日期应为 DateTime 格式 。它是日期和时间的普遍使用和首选格式 。对于人工解释 , 日期要么以 dd/mm/yyyy 格式提及,要么以 mm/dd/yyyy 格式提及,所使用的格式也必须提及 。
交易数据清理
【一文教你如何正确地清理数据】交易数据中的一个主要问题是 DateTime 违规 。数据中的日期和时间应该采用 Python 中的 datetime 格式 。如果需要,可以更容易地从列中提取单独的日期和时间 。在银行事务数据集中,日期列已采用日期时间格式 。因此,我们将处理数据集中的提取列 。要将列转换为 datetime , 请使用 panas.To _ datetime ()函数 。import datetime as dt
df.extraction=pd.to_datetime(df.extraction)
df.extraction
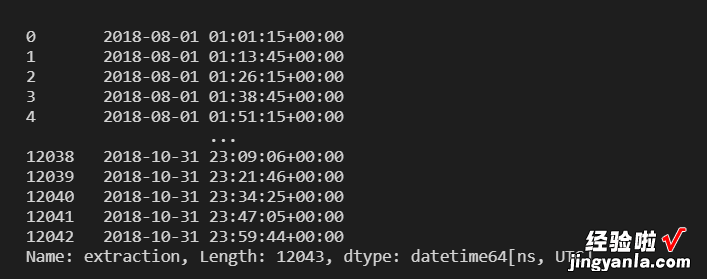
这里您可以看到数据类型是 datetime64 。
您可以对 datetime 对象进行大量操作 。
这里有一些例子-
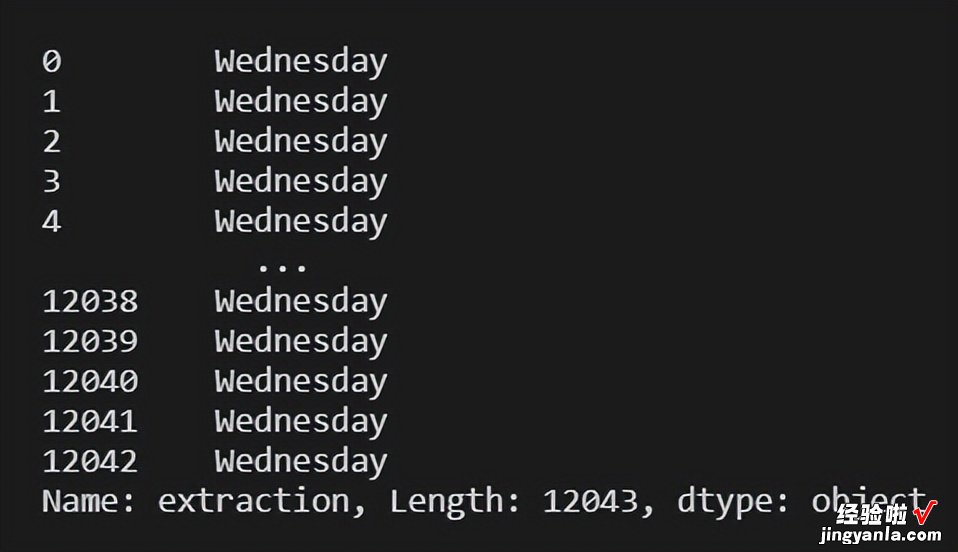
df.extraction.dt.day_name() #will return day of the week
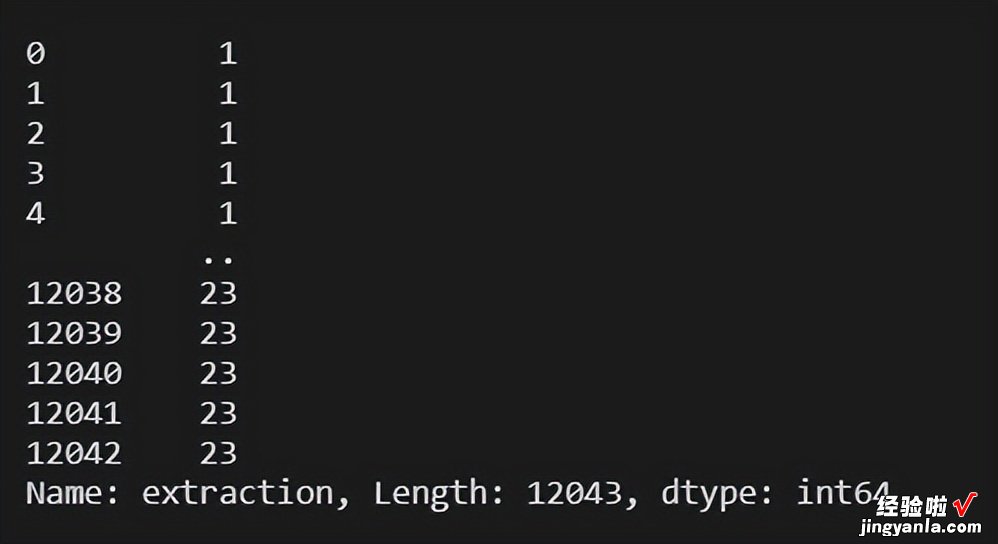
df.extraction.dt.hour #returns the hour of the day
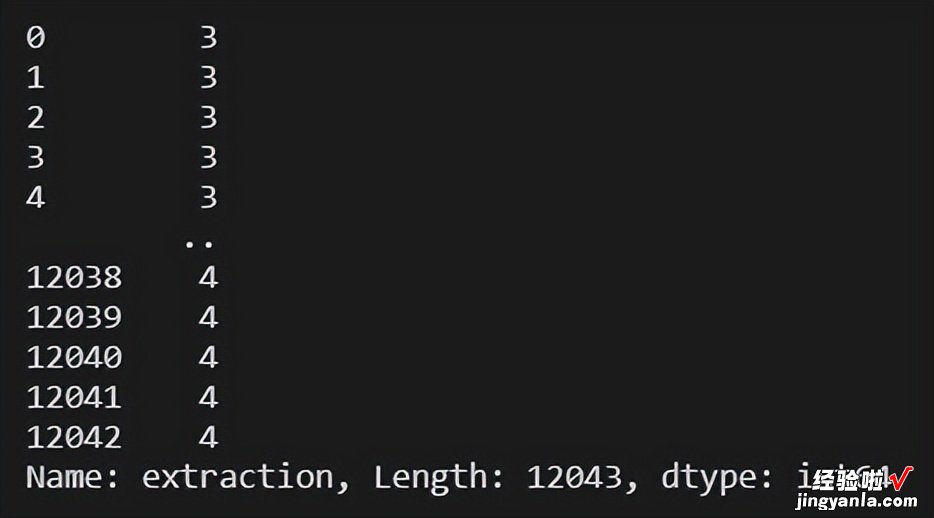
df.extraction.dt.quarter #returns which quarter of the year is it
df.extraction.dt.minute # returns minute of the hour
日期时间库是广泛而有用的,特别是在处理时间序列时 。日期时间的详细函数可以在这里找到 。
先前存在的软件
当最近的最后期限迫在眉睫时,所有这些步骤也可能变得相当乏味 。在这种情况下,有某些软件和网站,将执行所有这一切为您! !这里有一个全面的网站清单,你可以访问,使您的工作更容易 。学习数据清理的资源
有关数据清理方法和实践的更多深入信息,这里有一些有用的链接-- 数据清理: 问题和当前的方法
- 有效数据清理终极指南(免费电子书)
- 数据科学编程(免费电子书)
- Jeff Leek 的 GitHub 知识库
- 金融数据科学与特征工程 | Ernest P. Chan 博士 | QuantInsti Quantra
常见问题
数据清理、数据挖掘和数据争吵之间的区别是什么?数据清理是清除或纠正不准确或不完整数据的过程 。上面讨论的不同技术可用于执行数据清理 。另一方面 , 数据挖掘是从干净的数据中提取有价值的信息并从中得出推论的过程 。数据清理和数据挖掘的整个过程,如果同时进行,就称为数据争吵 。
什么是可重复的数据? 为什么它很重要?
可重复的数据意味着,如果其他人对同一数据使用相同的处理过程,那么他们必须得出相同的结论,你的数据处理方法必须以这种方式记录 。为此,不能手动对原始数据进行任何更改 。原始资料的副本必须保存,以供他人使用 。这样做将确保您的数据集是可信的,并且其他人可以信任它们的使用 。
什么是可靠和免费的数据源?
其中一种收集数据的方法是从网站上获取原始文本数据,然后进行清理 。另一种方法是从 Kaggle、 UCI 机器学习资料库和政府官方网站等网站获取数据 。这里的一篇非常有用的文章包含了一个数据集的综合列表 。其他网站包括:
- FiveThirtyEight
- BuzzFeed News
- Socrata
- Awesome-Public-Datasets on Github
- Google Public Datasets
- Academic Torrents
- Quandl
- Jeremy Singer-Vine
结论
总之,数据清洗是数据处理流水线的重要组成部分 。没有它,分析和机器学习建模将失败,并给出误导性的结果 。我们已经讨论了如何使数据集“干净”以及在处理数据时的注意事项 。我们现在知道如何计算空值、处理重复值和异常值、标准化数据和处理误导性字符串 。您还可以使用预先存在的软件自动清理您的数据!正如一句流行的谚语所说,“清洁仅次于虔诚”,让你的数据保持清洁 , 从而使你的结果保持干净 。