文|苏荨墨
编辑|苏荨墨

前言
在计算生物学中,排列检验已成为一种广泛使用的工具,用于评估正在调查的事件的统计显着性 。然而,计算表示统计显着性的P值的常用方法在要准确估计小 P值时需要非常大量的排列 , 这在计算上是昂贵的并且通常是不可行的 。
最近,我们提出了一种替代估计器 , 与标准经验方法相比 , 它需要更少的排列,同时仍然可靠地估计小P值 。

拟议的P值估计器已通过附加功能得到丰富,并通过称为 EPEPT 的公共网站和网络服务提供给普通社区 。
这意味着 EPEPT 例程不仅可以通过网站访问,还可以使用任何可以与网络交互的编程语言以编程方式访问 。
可以下载多种编程语言的 Web 服务客户端示例 。此外,EPEPT 接受计算生物学中使用的各种常见实验类型的数据 。

对于这些实验类型 , EPEPT 首先计算排列值,然后执行P值估计 。最后,可以下载EPEPT的源代码 。
测试中排列顺序法则的作用
排列检验(也称为随机化检验)是一种非参数程序,用于根据数据集标签的重新排列确定统计显着性 。由于其非参数性质,此测试通常用于生物信息学应用程序 , 在这些应用程序中通常没有确凿的证据或足够的数据来假设特定模型来获得所调查生物事件的测量值 。

例如 , 分别检测差异表达基因和基因集的微阵列显着性分析 (SAM) 和基因集富集分析 (GSEA) 是使用排列检验计算统计显着性的两种著名技术 。
在排列测试中 , 将从数据集计算的测试统计量与排列值的分布进行比较,这些排列值的计算类似于测试统计量 , 但在数据集标签的随机重新排列 。
表示其统计显着性的排列检验的P值是通过执行所有可能的标签排列并计算至少与从未排列的数据中获得的检验统计量一样极端的排列值的分数而获得的 。
然而,在实际情况下 , 执行所有可能的排列是不可行的,因此,P值通常通过计算有限数量的排列来近似,比如N,然后计算至少与检验统计量一样极端的N 个排列值的分数 。
这种计算P值的经验近似直接将可获得的最小P值和P值的分辨率与排列数耦合 , 因此,当要准确估计小P值时,需要非常大量的排列 。
为了改进经验估计,我们采用了基于极值理论的尾部估计程序来估计排列值分布的尾部以及随后的 P值 。
我们使用理论和实际示例表明,要以与经验方法相同的精度计算小的P值,最多需要减少几个数量级的排列 。
这导致计算时间方面的巨大收益 。对于使用标准数量的 1000 个排列的真实数据集 , 这种加速将导致 CPU 时间减少大约几分钟到几个小时 , 以用于更复杂的统计(如 GSEA 运行总和统计) 。该方法如图所示的图1中进行了详细描述 。
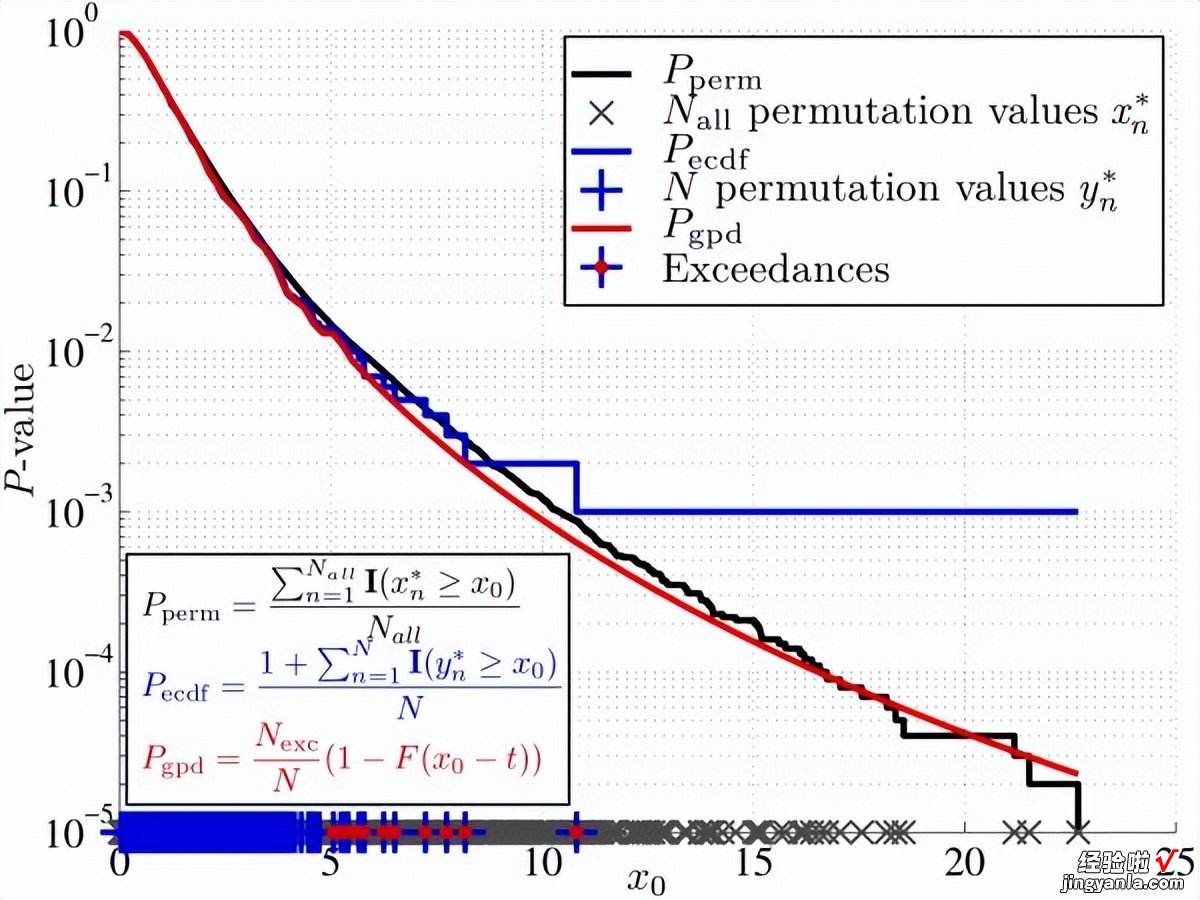
图1
EPEPT 的目的是使这种方法作为一种通用且易于访问的工具提供给计算生物学界 。EPEPT 代表用于置换测试的增强P值E估计器,是一种提供动态编程访问的RESTful Web API 。
用户使用他们选择的编程语言或使用网站通过网络提交工作请求 。EPEPT 返回与提交的作业相对应的唯一 URI 。
使用这个 URI , 可以检查提交作业的状态,完成后,可以检索结果 , 即估计的P值 。
EPEPT 可用于两种不同的设置 。在第一个也是最一般的设置中 , 用户提交排列值并且 EPEPT 估计P值,即 EPEPT 不生成排列统计数据 。
在第二种设置中,用户提交一个带标签的数据集,EPEPT 首先从中生成排列值 , 然后估计P值 。
实现了计算生物学中两个常用的实验设计:SAM 和 GSEA,分别用于检测差异表达的基因和基因集 。
当然,除了分别在 SAM 和 GSEA 中使用的 T 统计量或 Kolmogorov-Smirnov (KS) 统计量之外,还有许多策略可以从标记的数据集中计算排列统计量 。
一般来说,研究问题和使用的数据集决定了配方的定义,以根据标记的数据集计算排列统计 。
这种配方的规格可能非常详尽和复杂 。强制用户以特定格式语言提交此类规范会极大地限制 EPEPT 的可访问性和可用性 。
这就是为什么应提交排列值或应选择常见实验类型的原因,与用户协商 , 额外的实验设计(基于现有的 R 包或他们自己的特定数据和排列统计等 。

数据脚本中的请求
图2描绘了 EPEPT 的底层网络服务软件架构 。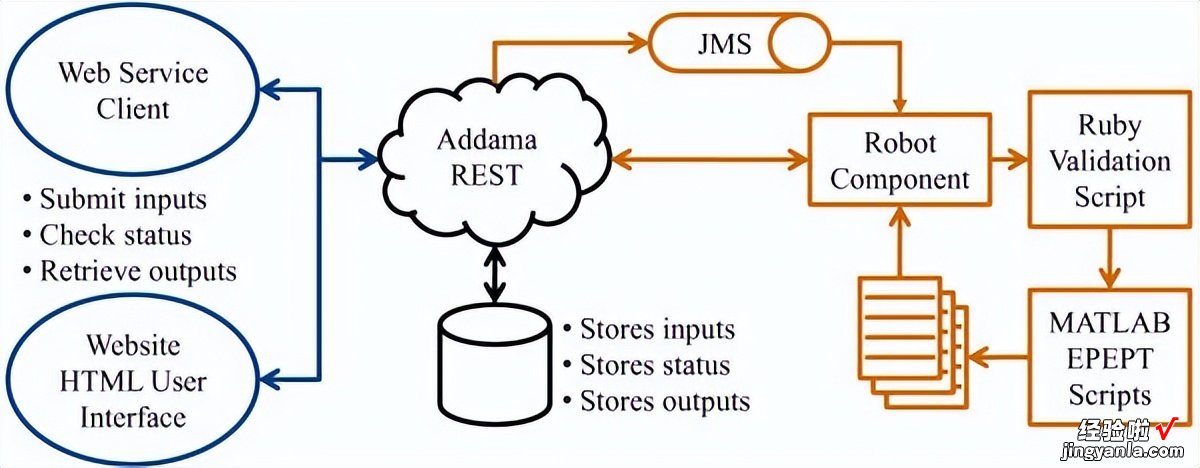
用户发出 HTTP POST 请求 , 其中包含描述其作业的输入参数,主要输入是一个包含测试统计数据及其相应排列值或标记数据集的文件 。
这取决于用户选择的设置,此外,可以指定一组参数,这些参数在使用部分有详细描述 , 该请求由 RESTful 自适应数据管理服务架构 (Addama) 处理 。
收到请求后,将广播 Java 消息服务 (JMS) 消息 。此消息由将协调作业执行的机器人组件使用 , 该作业在单独的服务器上运行 。
首先,它创建一个工作区,其中存储输入以及日志文件、执行期间作业的状态以及生成的输出 。用户可以通过在发出请求后发回的 URI 访问此工作区 。
然后,机器人组件启动两个脚本(按顺序):一个用于验证输入参数的 Ruby 脚本 , 然后是主 MATLAB 脚本 。
如果选择了常见的实验设计(SAM 或 GSEA),MATLAB 将调用适当的 R 包(samR 或 GSA)来计算排列统计量 。
基于上传或计算的排列统计,使用尾部估计程序的P值估计 。完成后,机器人组件会保留日志和输出 。

数据库在用户界面上的应用
在此 Web 服务之上,使用 HTML 和 ExtJS 构建了一个用户界面,ExtJS 是一个开源的跨浏览器 javascript 库 。该网站使用户能够上传排列值或标记的数据集并配置可选的输入参数 。
此外,结果窗格动态显示程序执行状态,并在完成时直观地表示估计的P值,允许用户将它们下载为制表符分隔的文本文件 。
结果窗格还显示执行时间和错误消息,该网站的屏幕截图以及示例结果如图所示图3 。
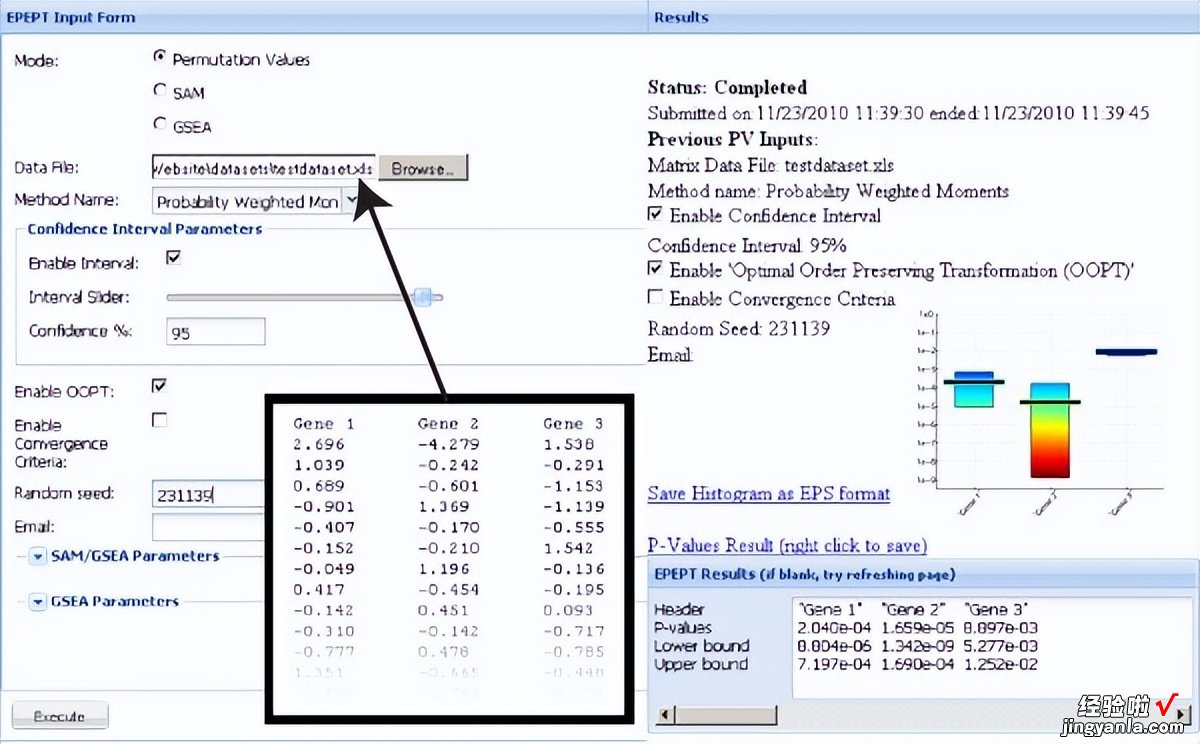
图3
EPEPT 可以在三种不同的设置下运行 。在第一个设置(“PV”)中,EPEPT 期望用户上传排列值 。
在第二个和第三个设置“SAM”和“GSEA”中 , EPEPT 假定已上传基因表达数据集 。
包含测试统计数据和排列值或标记基因表达数据集的文件 。
EPEPT 检查文件的扩展名以决定其格式:Excel 文件应具有 .xls 或 .xlsx 扩展名 , 数据应位于第一张工作表上 。
逗号分隔文件的扩展名应为csv,所有具有其他扩展名的文件都被假定为制表符分隔的文本文件 。
在“PV”设置中,文件中的每一列都应包含一个检验统计量及其对应的排列值 。
由于允许使用多个列,因此可以同时但独立地测试不同的事件(例如不同的基因或基因组) 。
文件允许有一个标题行,如果是标题行,则测试统计信息应位于第二行 。
如果没有使用标题行,则测试统计信息应位于第一行,假定检验统计量下方行中的所有数值都是排列值 。
忽略非数值、NaN(不是数字)和 Inf(无穷大),应报告每列至少 1,000 个排列值 , 以便使用尾部估计程序 。
在“SAM”和“GSEA”设置中,每一列都应包含数据集中所有基因的表达水平 。第一行应包含分配给列的类标签或其他响应类型 。
第一行的可能配置应与 samR 包的 'resp.type' 选项相匹配,第一列可用作基因名称的标题列 。
可以使用三种不同的方法来估计广义帕累托分布(对排列值分布的尾部进行建模)的参数:概率加权矩 (PWM)、最大似然法 (ML) 和矩法 (MOM) 。
通过理论分布和实际应用,我们发现所有方法的性能都相当 。一些研究比较了这些估计量,通常支持 ML 。
估计P值的置信区间表示估计的可靠性 。置信区间由置信水平(默认 95%)确定,该级别可设置在 10 到 99 之间,确定是否应计算置信区间的标志 。
如果给出 1 到 1,000,000 之间的数值,这将用作随机种子,允许用户重现 EPEPT 运行 。当选择(默认)值 0 时,随机种子将被任意选择 。
当 EPEPT 运行完成时,将向电子邮件地址(如果有说明)发送一封邮件 。此邮件包含指向结果和日志的链接 。
当 EPEPT 用于在“SAM”或“GSEA”设置中生成排列值时,用户可以选择响应类型 。
? 排列数[可选,默认 = 1000]
当 EPEPT 用于在“SAM”或“GSEA”设置中生成排列值时,用户可以选择要执行的排列数 。
在“SAM”设置中 , 最大值为 1,000 。(SAM 使用所有基因的排列值评估一个基因的P值,有效地将使用的排列数乘以基因数,在“GSEA”设置中,最大值为 10,000 。
? 基因集文件['GSEA'设置中需要]
当 EPEPT 用于在“GSEA”设置中生成排列值时,必须提供具有基因矩阵转置 (.gmt) 格式的基因集注释的文件 。
这种制表符分隔的文本文件每行包含一个基因集,前两列包含基因集 ID 和描述 。
以下列包含该特定基因组的基因 。这些基因的注释应与基因表达数据文件标题栏中的基因注释相匹配 。

输出数值的变化报告
EPEPT 的主要输出是一组估计的P值 , 这些在制表符分隔的文本文件中报告,如果在原始文件中提供了标头 , 则输出文件包含相同的标头 。如果要求置信区间,则具有P值估计的行下的两行表示置信区间的下限和上限,最后,如果应用了收敛标准 , 则在另一行中添加二进制值,指示估计是否收敛或不收敛 。
除了这个文本文件之外,还能生成了两个图片文件,它们直观地描述了估计的P值及其置信区间 。

结语
由于生物数据及其分析的计算复杂性的巨大增加,计算生物学正在转向基于客户端-服务器的计算模型 。在这些模型中,计算分析不再在桌面上执行,而是将任务分包给不同的(基于网络的)服务提供商 , 例如网络集群、网络服务或云计算环境 。
事实上,除了对数据库的编程访问外,越来越多的生物信息学工具也可以使用编程访问 。
在这里,我们介绍了 EPEPT , 这是一种网络服务工具,用于根据极值理论估计排列检验的P值 。
EPEPT 估计器形成了标准经验估计器的一个有价值的替代方案 , 因为它可以在(经常发生的)情况下提供准确的P值估计,其中没有或只有很少的排列值超过检验统计量,即使相当数量的排列已经被执行 。
对这些例程的编程访问对于旨在使用他们选择的编程语言系统地测试许多假设(例如许多基因或基因集)的计算生物学家来说是实用的 。
【在排序测试中,计算方法显示P值常用的方法有几种?】此外,EPEPT 可以很容易地集成到自动工作流程中 。