一点前言
直接来说,这种很多程序员的梦想~ 撸了大半辈子的代码,号称可以把宇宙Coding出来,结果到了Excel这块卡主了 。我就是想写SQL去查Excel,不喜欢记住那么多Excel操作! 好在,我们这个世界变化很快,Excel新的版本号称是支持python的 , 也准备支持js,不过有个问题是当年一直追随window的程序员因为技术提升有了Mac了,新版本的office目测还收费,en~ 我在玩Spark的时候发现可以搞Excel,秃秃的脑袋瓜一转~~起手
不得不说真需要狠狠感谢这个开源的世界,以及基础环境的搭建人员 。首先,我们看到了一个github上面的开源项目:spark-excel[1] 其次 , 在github网络不通的背景下,我们找到了gitee上面的镜像地址:可用的地址[2] , 剩下的工作我们就是调通 。引入
这个其实是一个sbt下的工程,所以我们可以直接用maven引入com.crealytics spark-excel_2.110.11.1 当然,根据Scala版本的不同可以有不一样的配方
Scala 2.12
groupId: com.crealyticsartifactId: spark-excel_2.12version: _0.14.0Scala 2.11
groupId: com.crealyticsartifactId: spark-excel_2.11version: _0.14.0如果还有特殊版本 , 公司内部版本,源码编译方式也是提供了 。
起手
上手自然先准备一把Excel数据,先弄一个excel的数据表格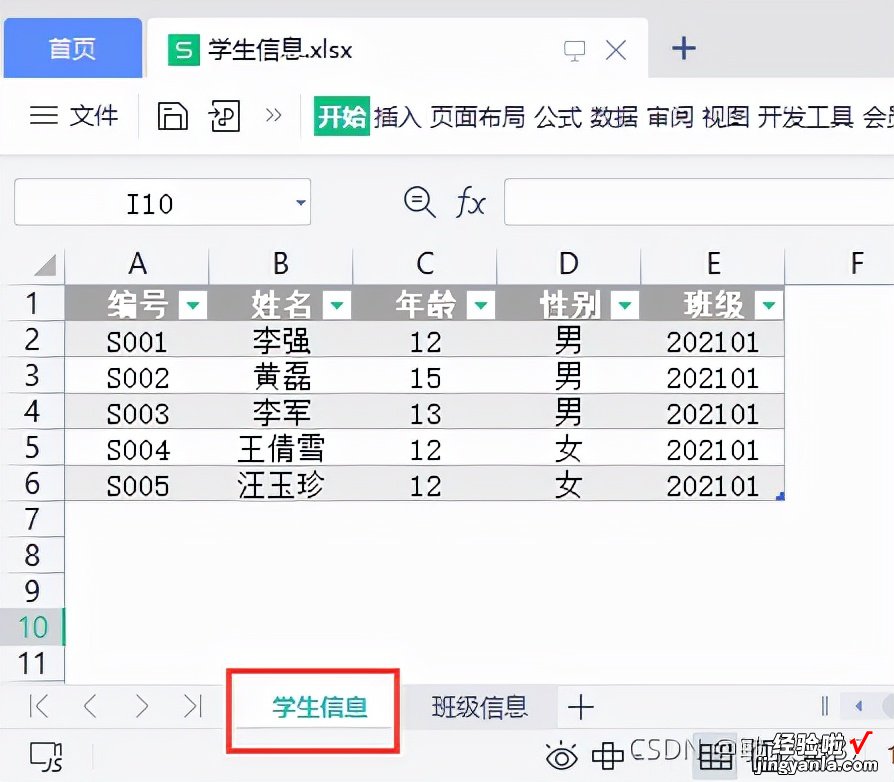
数据ready , 我们进行编码,初始化之类的跳过,需要读取excel的话首先要构建schema,这个是后面读取数据需要的列
【利用SparkSQL读写Excel数据】
//定义数据结构val schema = StructType(List(StructField("id", StringType, nullable = false),StructField("name", StringType, nullable = false),StructField("age", IntegerType, nullable = false),StructField("gender", StringType, nullable = false),StructField("cls", StringType, nullable = false)))读取数据
val df = spark.read.format("com.crealytics.spark.excel").option("dataAddress", "'学生信息'!A2:E6").option("useHeader", "false").schema(schema).load(filePath)df.show()代码执行,结果如下:
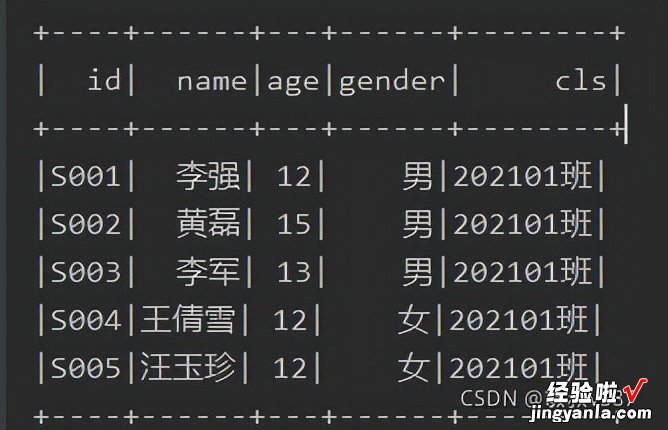
读取的时候有挺多配置的,适宜各种场景下需要定制化执行,关键配置进行说明 |配置项 | 说明 | |--|--| | dataAddress | 学生信息'!A2:E6,这个表示的其实是Sheet中表格的范围,我指定的是A2到E6表示的其实是一个对角线的区域 | |useHeader| 必须,是否使用表头,false的话自己命名表头(_c0),true则第一行为表头| 更多配置的话参考源码中的文档或者看源码也是可以的 。
实战
目标:前面有一个学生表,我们再搞一个班级表我们目标是把学生对应的班主任合并到一个sheet里面去 。我们增加一个对班级读取的df
val clsSchema = StructType(List(StructField("cls_id", StringType, nullable = false),StructField("cls_addr", StringType, nullable = false),StructField("headteacher", StringType, nullable = false))) val clsDf = spark.read.format("com.crealytics.spark.excel").option("dataAddress", "'班级信息'!A2:C2").option("useHeader", "false").option("treatEmptyValuesAsNulls", "true").option("inferSchema", "true").schema(clsSchema).load(filePath)clsDf.show(10)分别建立自己的表视图
studentDf.createOrReplaceTempView("student")clsDf.createOrReplaceTempView("cls")激动人心的撸sql环节就来了
val sql="""|select id,name,age,gender,cls,cls_addr,headteacher from|student left join cls on student.cls=cls.cls_id|""".stripMarginspark.sql(sql).show(100)看一下结果
最后我们把结果写到excel中
val savefilePath = "D:\学生信息详情.xlsx" val stuDetail = spark.sql(sql)stuDetail.write.format("com.crealytics.spark.excel").option("dataAddress", "'学生详情'!A1").option("useHeader", "false").option("header", "true").mode("append").save(savefilePath)效果如下:
通关 ~