许多程序员新人想了解爬虫的实现,然而,网络上的许多信息是教大家如何爬虫工具 。工具的使用对于快速完成页面爬取工作是有帮助的,但不利于大家掌握爬虫的原理 。
本文将带大家从最基本和最本质的途径去编写一个爬虫,让大家真正了解爬虫的工作原理 。并且,能够在此基础上根据自身需求改造出需要的爬虫 。
网页的组成
在开始爬虫工作之前,我们先了解下 , 什么是网页 。
以某网页为例 , 其展示效果如下:、

我们在网页上点击右键 , “查看源代码”可以看到网页的代码信息,如下:

其中有很多文本,也有很多链接 。这些链接有的指向另一个页面 , 有的指向css文件、js文件、图片文件等 。
分类一下 , 网页一共包含以下几个部分,如图所示 。
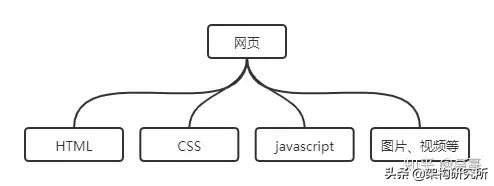
各个部分的含义如下:
- 其中HTML是网页的主要部分,存储了网页的主要内容
- CSS则是对网页中的内容进行修饰
- Js则是对网页增加一些动态的功能
- 图片、视频则是一些辅助的材料
爬虫的基本原理
而爬虫的一个重要特点就是顺藤摸瓜——根据链接,从一个网页跳转到另一个网页,不断进行 。从而获取众多网页的信息 。
那实现爬虫,要完成的基本功能是:
- 爬?。ㄏ略兀┠掣鐾?/li>
- 查找当前网页中的链接,继续爬取
爬虫(网页地址)爬取某个页面分析页面中的链接使用分析得到的链接再次调用方法爬虫(网页地址)对的,你没看错,就是这么简单 。
其中有两个功能需要实现,即爬取某个页面、分析页面中的链接 。
接下来我们分别介绍这两个功能的实现 。
核心功能的实现
1 爬取某个页面
这个功能使用Python实现起来比较简单,只要打开一个文本,然后将网络某地址的信息写入文本就算是爬取完成了 。实现代码如下 。
htmlFile=open('./output/' (str(pageId) '.txt'),'w')htmlFile.write(urllib.urlopen(url).read())htmlFile.close()2 分析页面中的链接
该工作需要正则表达式的帮助,'href="[^(javascript)]S*[^(#)(css)(js)(ico)]"'可以帮助我们匹配出网页中的链接 。pattern=re.compile('href="[^(javascript)]S*[^(#)(css)(js)(ico)]"')htmlFile=open('./output/' (str(pageId) '.txt'),'r')for line in htmlFile:ans=re.findall(pattern,line)爬虫的实现
有了伪代码和两个核心功能的实现代码后,我们可以直接写出爬虫的主要代码:
htmlFile=open('./output/' (str(pageId) '.txt'),'w')htmlFile.write(urllib.urlopen(url).read())htmlFile.close()htmlFile=open('./output/' (str(pageId) '.txt'),'r')for line in htmlFile:ans=re.findall(pattern,line)for one in ans :urlTail=one.split('"')[1]url=urlparse.urljoin(url,urlTail)if urlMap.has_key(url):print 'skip---' urlelse:print 'download---' urlpageId= 1urlMap[url]=pageIdidMap[pageId]=urlcatchFile=open('./output/' (str(urlMap[url]) '.txt'),'w')try:catchFile.write(urllib.urlopen(url).read())except:passfinally:catchFile.close()htmlFile.close()即爬取某个页面、分析页面中的链接、继续下载 。
当然,在这个过程中,有几点要注意:
1、遇到死链要跳过 , 不要一直卡在那里
2、凡是下载过的页面不要重复下载,否则可能形成环路,永无止境
只要注意了以上两点,就可以写出爬虫 。
我直接给出爬虫的代码,放在下面的开源地址上 。
https://github.com/yeecode/EasyCrawler
现有功能与展望
该爬虫十分基础、简单、容易理解,就是上面伪代码的直接实现 。该爬虫的基本功能如下:
- 输入一个入口地址后,会爬取该地址网页中`href=https://www.itzhengshu.com/wps/`指向的页面 , 并将内容下载下来,依次保存
- 对于不能访问的坏链接,将会忽略
- 该爬虫只能爬取入口地址的链接 , 不再向更深处爬取
- 会自动给页面编ID,并跳过已爬取的页面
基于以上功能 , 我们可以修改实现众多其他功能,包括但不限于:
- 根据页面不断爬取 , 而不是只爬取一层链接
- 设置爬取范围,例如只爬取某个域名下的链接
- 定时爬取某个地址的数据,并对比其变化
- 只爬取网页中的图片信息
- 等等……
往期精彩文章:
- 程序员最有成就感的那一刻是什么时候?
- 远程过程调用RPC的实现原理:动态代理
【零基础学会网页爬虫编写?这篇文章就够了】欢迎关注我们,不错过软件架构和编程方面的干货知识 。