前言
在AI浪潮风起云涌的当下,AI正在不断地重塑着每一个行业 。笔者的目标是在公众号中把所有当下流行的AI应用都梳理一遍,在整理技术拓展思路的同时也给大家做一个科普 。有一段时间没有介绍aigc相关的应用了,今天翻到了一个很早之前调研过的火了很久的一个项目—pdfGPT 。PDF GPT允许你使用GPT功能与上传的PDF文件进行聊天 。这时候看过笔者推文的同学就会问,这个项目和Quivr有什么区别呢?实际上,这个项目比Quivr要早,只是Quivr适配了更多的数据类型,比如文本、图片、代码片段,应有尽有 。对Quivr感兴趣的可以翻一下之前的文章:Quivr - 你的第二个大脑,由AIGC赋能
【pdfGPT——通过AI与上传的PDF文件进行聊天】本篇文章的目的更多是为了整理和科普,后面笔者会输出一些AI实战应用的文章,小伙伴们可以持续关注一下 。本篇的pdfGPT项目的github地址为:https://github.com/bhaskatripathi/pdfGPT
pdfGPT
演示
1.演示URL: https://bit.ly/41ZXBJM注意: 如果你喜欢这个项目,请给它点赞!
问题描述 :
1.当你向Open AI传递大量文本时,它会受到4K令牌限制 。它不能将整个pdf文件作为输入2.Open AI有时会变得过于健谈,并返回与你的查询无直接关系的无关应答 。这是因为Open AI使用了质量较差的嵌入 。
3.ChatGPT不能直接与外部数据进行交互 。一些解决方案使用Langchain,但如果没有正确实现 , 它会消耗大量的令牌 。
4.有许多解决方案 , 如https://www.chatpdf.com, https://www.bespacific.com/chat-with-any-pdf, https://www.filechat.io,它们的内容质量较差,容易产生幻觉问题 。避免幻觉并提高真实性的一个好方法是使用改进的嵌入 。为了解决这个问题,我建议使用Universal Sentence Encoder系列算法来改进嵌入(在这里阅读更多:https://tfhub.dev/google/collections/universal-sentence-encoder/1) 。
解决方案: 什么是PDF GPT ?
1.PDF GPT允许你使用GPT功能与上传的PDF文件进行聊天 。2.该应用程序智能地将文档分解成更小的块,并使用强大的Deep Averaging Network Encoder生成嵌入 。3.首先在你的pdf内容上进行语义搜索,然后将最相关的嵌入传递给Open AI 。4.自定义逻辑生成精确的响应 。返回的响应甚至可以在方括号([])中引用信息所在的页码,增加了响应的可信度,帮助快速定位相关信息 。这些响应比Open AI的原始响应要好得多 。5.Andrej Karpathy在这篇文章中提到,对于类似的问题,KNN算法是最合适的:https://twitter.com/karpathy/status/16470252305468866586.使用langchain-serve[1]在生产环境中启用API 。Docker
运行docker-compose -f docker-compose.yaml up使用Docker compose 。使用langchain-serve[2]在生产环境中使用pdfGPT
本地游乐场
1.在一个终端上运行lc-serve deploy local api使用langchain-serve将应用程序作为API暴露出来 。2.在另一个终端上运行python app.py进行本地gradio游乐场 。3.在你的浏览器上打开http://localhost:7860并与应用程序进行交互 。云部署
通过在Jina Cloud[3]上部署使pdfGPT生产就绪 。lc-serve deploy jcloud api
显示命令输出【公众号格式问题,请移步原文】
使用cURL进行交互
(将URL更改为你自己的端点)PDF url
curl -X 'POST''https://langchain-3ff4ab2c9d.wolf.jina.ai/ask_url'-H 'accept: application/json'-H 'Content-Type: application/json'-d '{"url": "https://uiic.co.in/sites/default/files/uploads/downloadcenter/Arogya Sanjeevani Policy CIS_2.pdf","question": "What'''s the cap on room rent?","envs": {"OPENAI_API_KEY": "'"${OPENAI_API_KEY}"'"}}'{"result":" Room rent is subject to a maximum of INR 5,000 per day as specified in the Arogya Sanjeevani Policy [Page no. 1].","error":"","stdout":""}PDF文件
QPARAMS=$(echo -n 'input_data='https://www.itzhengshu.com/pdf/$(echo -n'{"question": "What'''s the cap on room rent?", "envs": {"OPENAI_API_KEY": "'"${OPENAI_API_KEY}"'"}}' | jq -s -R -r @uri))curl -X 'POST''https://langchain-3ff4ab2c9d.wolf.jina.ai/ask_file?'"${QPARAMS}"-H 'accept: application/json'-H 'Content-Type: multipart/form-data'-F 'file=@Arogya_Sanjeevani_Policy_CIS_2.pdf;type=application/pdf'{"result":" Room rent is subject to a maximum of INR 5,000 per day as specified in在Arogya Sanjeevani Policy [Page no. 1].","error":"","stdout":""}在本地主机上运行
鸣谢 : Adithya S[4]
1.通过在你的终端或命令提示符中输入以下命令来拉取镜像: docker pull registry.hf.space/bhaskartripathi-pdfchatter:latest1.将Universal Sentence Encoder下载到你的项目的根文件夹 。这很重要,因为否则,每次运行时都会下载915 MB 。2.使用这个链接[5]下载编码器 。3.解压下载的文件 , 并将其放在你的项目的根文件夹中,如下所示:
你的项目的根文件夹└───Universal Sentence Encoder|├───assets|└───variables|└───saved_model.pb|└───app.py4. 如果你已经在本地下载了它,将API文件中第68行的代码:
self.use = hub.load('https://tfhub.dev/google/universal-sentence-encoder/4')替换为:
self.use = hub.load('./Universal Sentence Encoder/')5. 现在,要运行PDF-GPT,输入以下命令:
docker run -it -p 7860:7860 --platform=linux/amd64 registry.hf.space/bhaskartripathi-pdfchatter:latest python app.py原始源代码 (托管在Hugging Face的演示) : https://huggingface.co/spaces/bhaskartripathi/pdfChatter/blob/main/app.py
UML

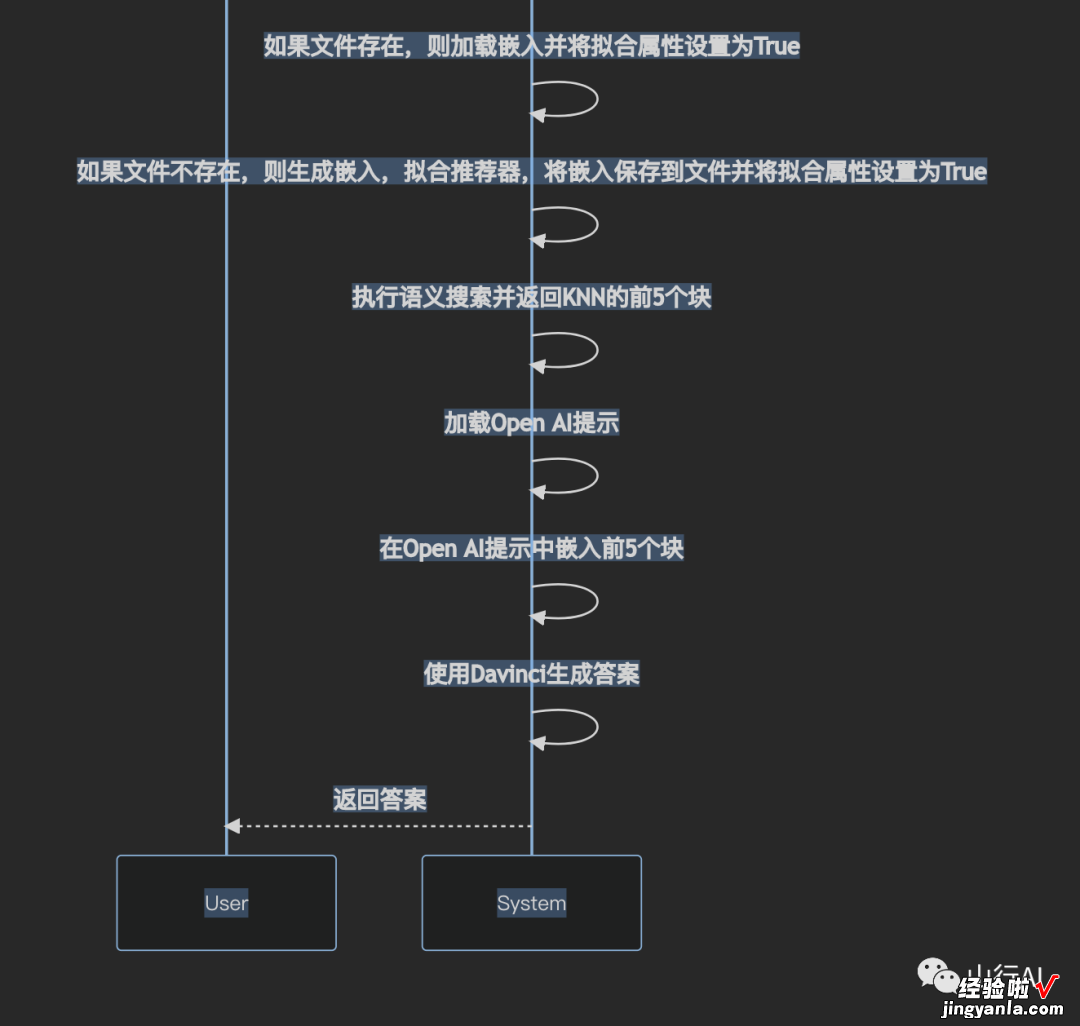
sequenceDiagramparticipant Userparticipant SystemUser->>System: 输入API密钥User->>System: 上传PDF/PDF URLUser->>System: 提问User->>System: 提交行动呼吁System->>System: 空字段验证System->>System: 将PDF转换为文本System->>System: 将文本分解为块(150字长度)System->>System: 检查是否存在嵌入文件System->>System: 如果文件存在 , 则加载嵌入并将拟合属性设置为TrueSystem->>System: 如果文件不存在,则生成嵌入 , 拟合推荐器,将嵌入保存到文件并将拟合属性设置为TrueSystem->>System: 执行语义搜索并返回KNN的前5个块System->>System: 加载Open AI提示System->>System: 在Open AI提示中嵌入前5个块System->>System: 使用Davinci生成答案System-->>User: 返回答案流程图

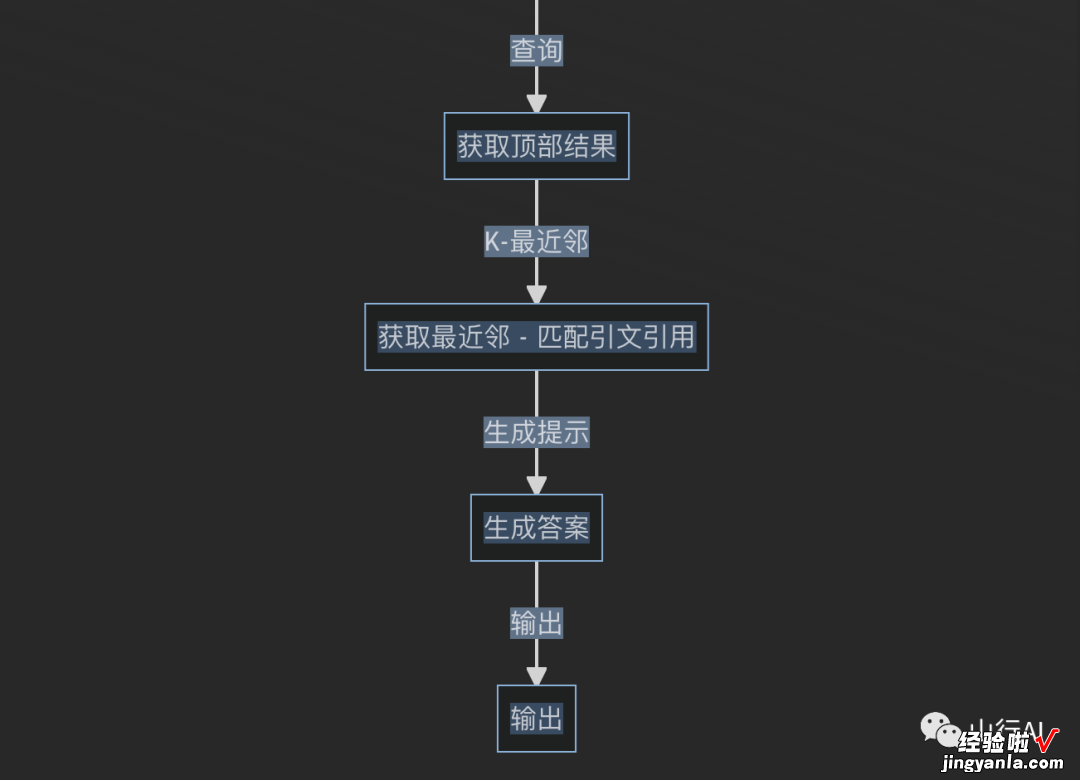
flowchart TBA[输入] --> B[URL]A -- 手动上传文件 --> C[解析PDF]B -->D[解析PDF] -- 预处理 --> E[动态文本块]C -- 预处理 --> E[动态文本块与引文历史]E --拟合-->F[使用Deep Averaging Network Encoder在每个块上生成文本嵌入]F -- 查询 --> G[获取顶部结果]G -- K-最近邻 --> K[获取最近邻 - 匹配引文引用]K -- 生成提示 --> H[生成答案]H -- 输出 --> I[输出]