爬取思路
- 使用selenium打开页面
- 输入需要解析的VIP视频URL
- 主动触发点击事件
- 切换iframe到找到video标签的src属性值
- 根据URL下载
源代码
源码目前只爬取到下载的URL,下载将会在后面补上from selenium import webdriverclass TencentVideo(object):"""腾讯视频爬虫""""""初始化方法,传入腾讯视频待解析的的url"""def __init__(self, parse_web_type, parse_web_url, video_url):driver = webdriver.Chrome()# 使用驱动获取一个解析网址driver.get(parse_web_url)print("打开成功")# 如果解析类型是wpsseo,按照http://www.wpsseo.cn/进行VIP解析if "wpsseo".__eq__(parse_web_type):# 1、获取输入框的值,并发送数据driver.find_element(by="id", value="https://www.itzhengshu.com/wps/url").send_keys(video_url)print("输入url成功:%s" % video_url)# 2、点击开始解析driver.find_element(by="id", value="https://www.itzhengshu.com/wps/bf").click()print("点击解析成功")# 3、根据不同的解析网站嵌套的iframe可能不一样iframe = driver.find_element(by="id", value="https://www.itzhengshu.com/wps/player")print("获取iframe成功")driver.switch_to.frame(iframe)print("切换到iframe成功")# 这里的第一个WANG的标签很重要,里面嵌套的内容有动态变化,可能是内嵌的访问腾讯的视频也可能是中间网站的地址iframe_wang = driver.find_element(by="id", value="https://www.itzhengshu.com/wps/WANG")driver.switch_to.frame(iframe_wang)print("切换到WANG的iframe成功")try:# 3.1、套娃了一个iframeiframe_no = driver.find_element(by="tag name", value="https://www.itzhengshu.com/wps/iframe")driver.switch_to.frame(iframe_no)# 3.2、iframe 里面又套娃了一个iframeWANG_2 = driver.find_element(by="id", value="https://www.itzhengshu.com/wps/WANG")driver.switch_to.frame(WANG_2)print("切换到WANG的iframe的myiframe成功----从解析网站获取")try:# 3.3、没有套娃了,直接通过video标签名称获取video_src = https://www.itzhengshu.com/wps/driver.find_element(by="id", value="https://www.itzhengshu.com/wps/video").find_element(by="tag name", value="https://www.itzhengshu.com/wps/video").get_attribute("src")print("获取链接成功:%s" % video_src)except:# 3.4、套娃里面还是套娃,又嵌套可一层iframemyiframe = driver.find_element(by="id", value="https://www.itzhengshu.com/wps/myiframe")driver.switch_to.frame(myiframe)try:# 3.4、最深处终于找到了video标签video_src = https://www.itzhengshu.com/wps/driver.find_element(by="tag name", value="https://www.itzhengshu.com/wps/video").get_attribute("src")print("获取链接成功:%s" % video_src)except:print("获取失败")except:try:# 判断这里的video标签时在div上还是在video上,video_tag = driver.find_element(by="id", value="https://www.itzhengshu.com/wps/video")if video_tag.tag_name == "video":# 3.5、直接字video上的话 src属性加了blob前缀,需要解析改格式才能下载video_src = https://www.itzhengshu.com/wps/video_tag.get_attribute("src")# blood开头的print("获取链接成功:%s" % video_src)else:# 3.6、 非常重要, 多次执行后总会有一次走到这里# 这里直接走的是腾讯视频的接口,如果研究一下改接口 应该也是大有收获video_src = https://www.itzhengshu.com/wps/video_tag.find_element(by="tag name", value="https://www.itzhengshu.com/wps/video").get_attribute("src")print("获取链接成功:%s" % video_src)except:print("下载失败")driver.close()driver.quit()if __name__ == '__main__':tv = TencentVideo("wpsseo", "http://www.wpsseo.cn/", "https://v.qq.com/x/cover/m441e3rjq9kwpsc/l0043ly8ohx.html")关键爬取截图
blob格式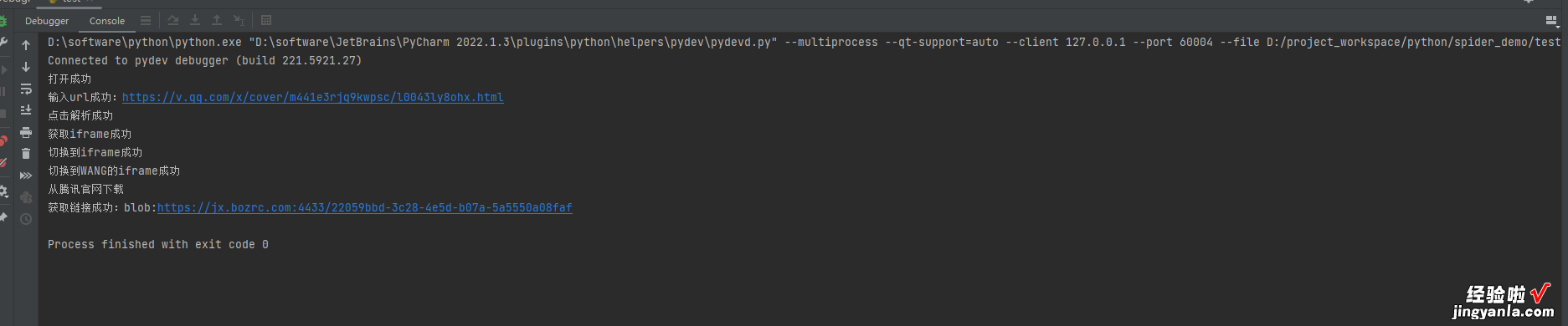
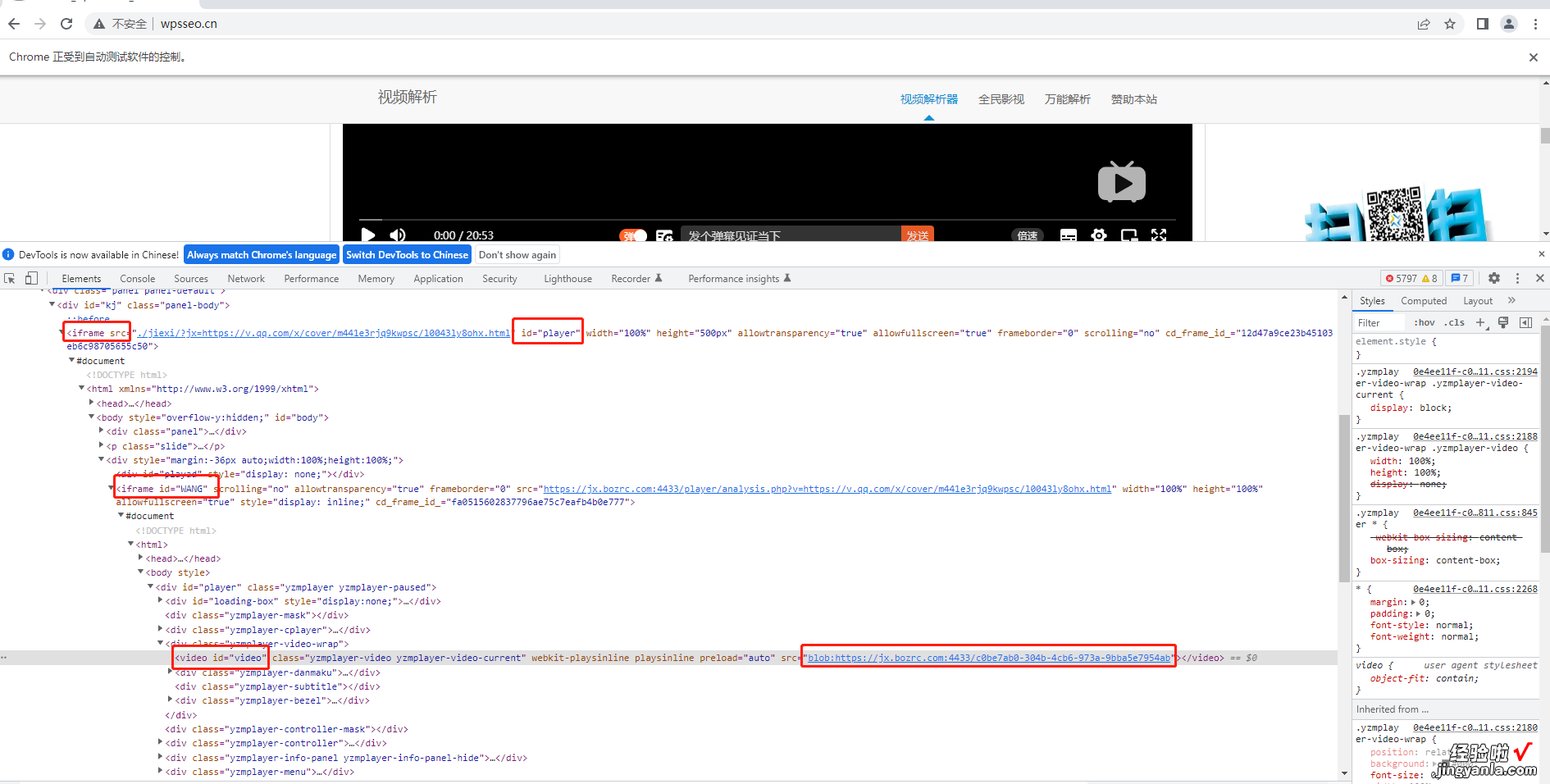
最深套娃
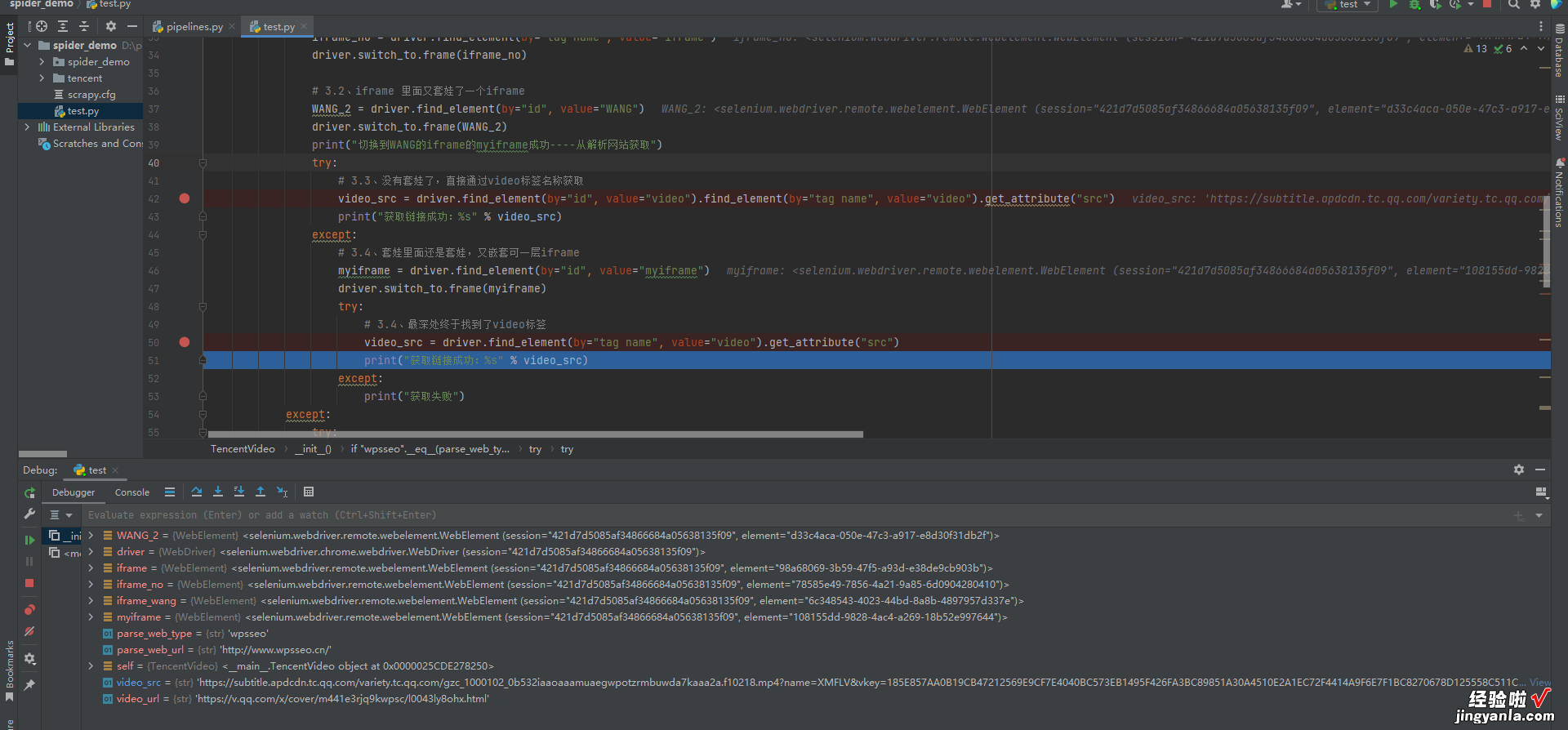

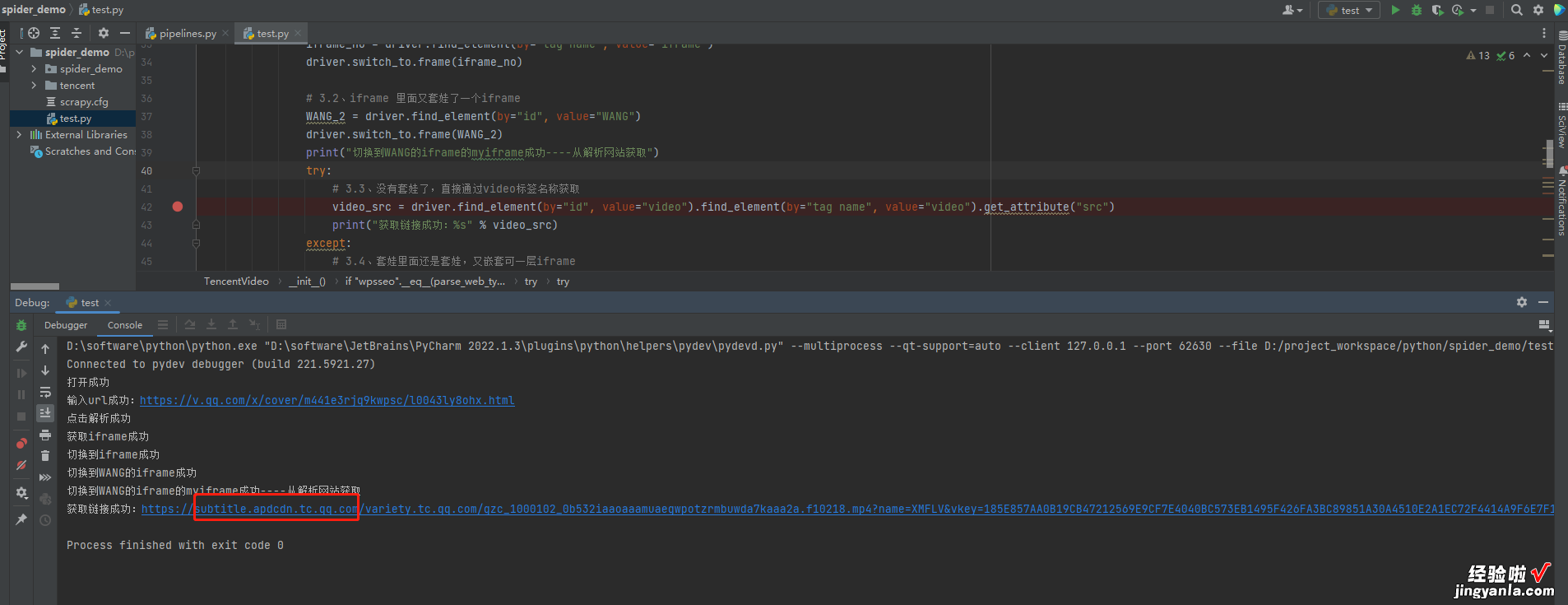
视频截图



【「python学习」 python爬取vip视频-01】此方法仅供学习,望大家看在套娃这么多的份上,小星星来一个哇!