随机对照试验可以得到较为可靠的证据,在预防医学研究和临床医学研究中扮演非常重要的角色 。人体试验中,实验组和对照组受试对象的特征(如年龄、性别、是否服药、是否有运动习惯等等)常成为研究过程中的混杂因素,对研究结果产生重要影响 。
因此,通常我们会采用随机分组的方法,将可能干扰试验结果的混杂因素较均匀地分配至不同研究组,使得组间基线情况均衡、减少混杂偏倚,以期得到比较真实的试验研究结果 。
相信大家已经听了很多次随机对照研究了,但是对于怎么个随机分组、怎么个分配隐藏法儿是不是不太了解呢?今天小编就和大家聊聊~
科研猫公众号后台对话框发送期刊名称(支持缩写、简写),即可查询期刊最新影响因子、近5年IF和发文量、期刊预警、分区等~
1.随机化
随机:通常有两种用途,一种是随机抽样,另一种是随机分组(随机化) 。
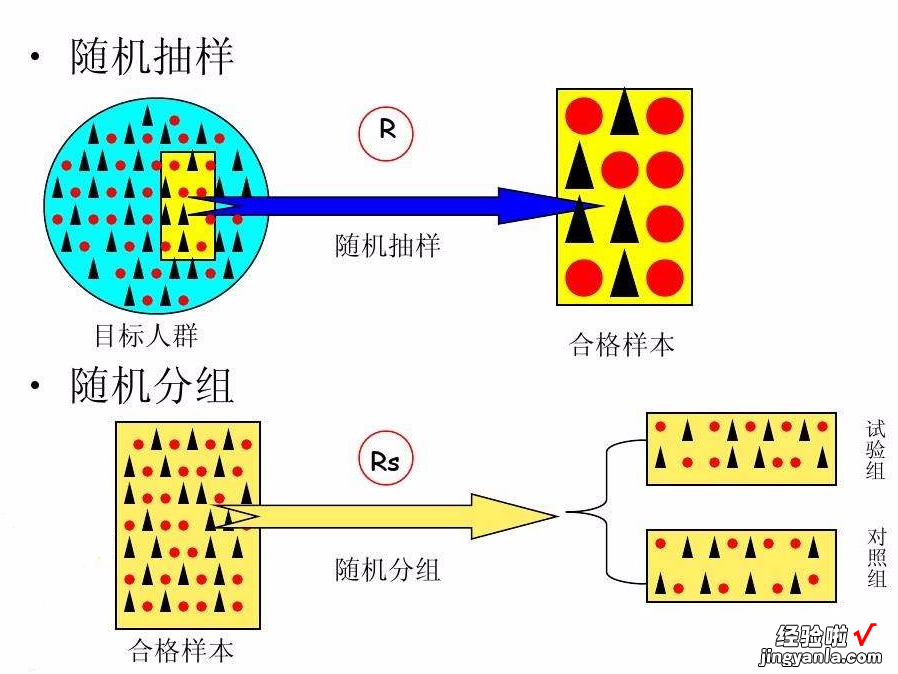
随机分组:每位研究对象被分配到实验组或对照组的机会相等,而不受研究者或受试者的主观愿望或客观因素所影响 。分组后要求组间基线特征基本均衡、组间研究对象人数基本相等、组间重要协变量均衡(重要协变量指与主要评价指标具有较强相关关系的因子) 。
01.简单随机化
简单随机化(Simple Randomization):也称为完全随机化,指以个体为单位将研究对象按照设定的比例(如1:1、1:2,或不加限制)分配到不同的组中 。
常用方法:是利用随机数字表或随机排列表,也可以用抽签或者抛硬币等方法;
适用条件:在研究例数较少、总体中个体差异较小时 , 采用此法 。
缺点:在受试者例数较少时 , 由于随机误差难以保证组间受试者例数的均衡,各组例数可能会出现不平衡现象 。有研究表明,当总例数为100时,每组刚好50例的概率仅为8% 。
例1:某研究计划入组100例研究对象,分为两组 , 分别使用试验药物和安慰剂 , 比较其治疗效果 。如何实现随机化分组?
- 事先拟定100个研究对象序号;
- 产生随机数字(此处用随机数字表法)
- 规定随机数字为奇数的研究对象分到A组,偶数分到B组;
- 规定A组使用试验药物,B组使用安慰剂;
- 留存随机分配方案的文件(部分分组结果见下表) 。

2.区组随机化
区组随机化(Block Randomization):根据受试者的某些特征,将特征相同或相似的受试者归入同一个区组,然后对同一个区组内的受试者实施随机化分组的方法,称为区组随机化 。
简单理解为是指将符合纳排标准的研究对象分成若干个区组,就像一列火车中几个容纳一定数量乘客的车厢;然后将每一个车厢(区组)内部的受试者按一定的分配比例(通常是1∶1)随机分配到各比较组 。即每个车厢中有一半的研究对象进入试验组 , 另一半的研究对象进入对照组 。
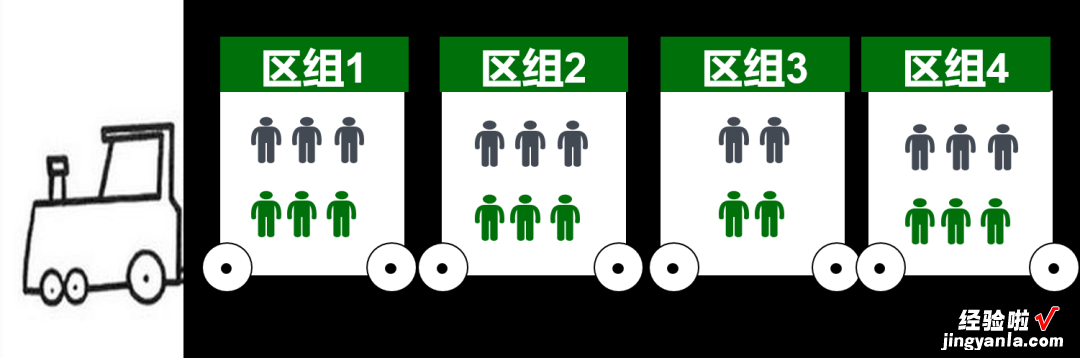
应用条件:当研究对象人数较少,而影响试验结果的因素又较多,简单随机化不易使两组具有较好的可比性时 , 可采用区组随机化 。
区组长度:一个区组研究对象的数量 。区组长度至少是研究组数的2倍,建议区组长度设置为4-10 。区组大小亦可不固定,如随机选取区组大小4和6或6和8 。区组随机化时,要先设定区组长度 。
优点:①平衡了人组时间对受试者特征的影响,保证了组间均衡性;②相对于完全随机设计 , 尽可能地保证了两组人数的一致 , 两组间人数的最大差异为区组大小的一半;③相对于完全随机设计,因提高了区组内个体的同质性,而提高了检验效能 。
缺点: 分组带有一定的可预见性,尤其是在开发试验中 。如第3个受试者看到前2个受试者均分配至B组,则知道自己将分配至A组 。为减少这种预见性,可采用不固定区组大小的策略(区组大小4 、6 混用),但这会增加实际操作的困难 。
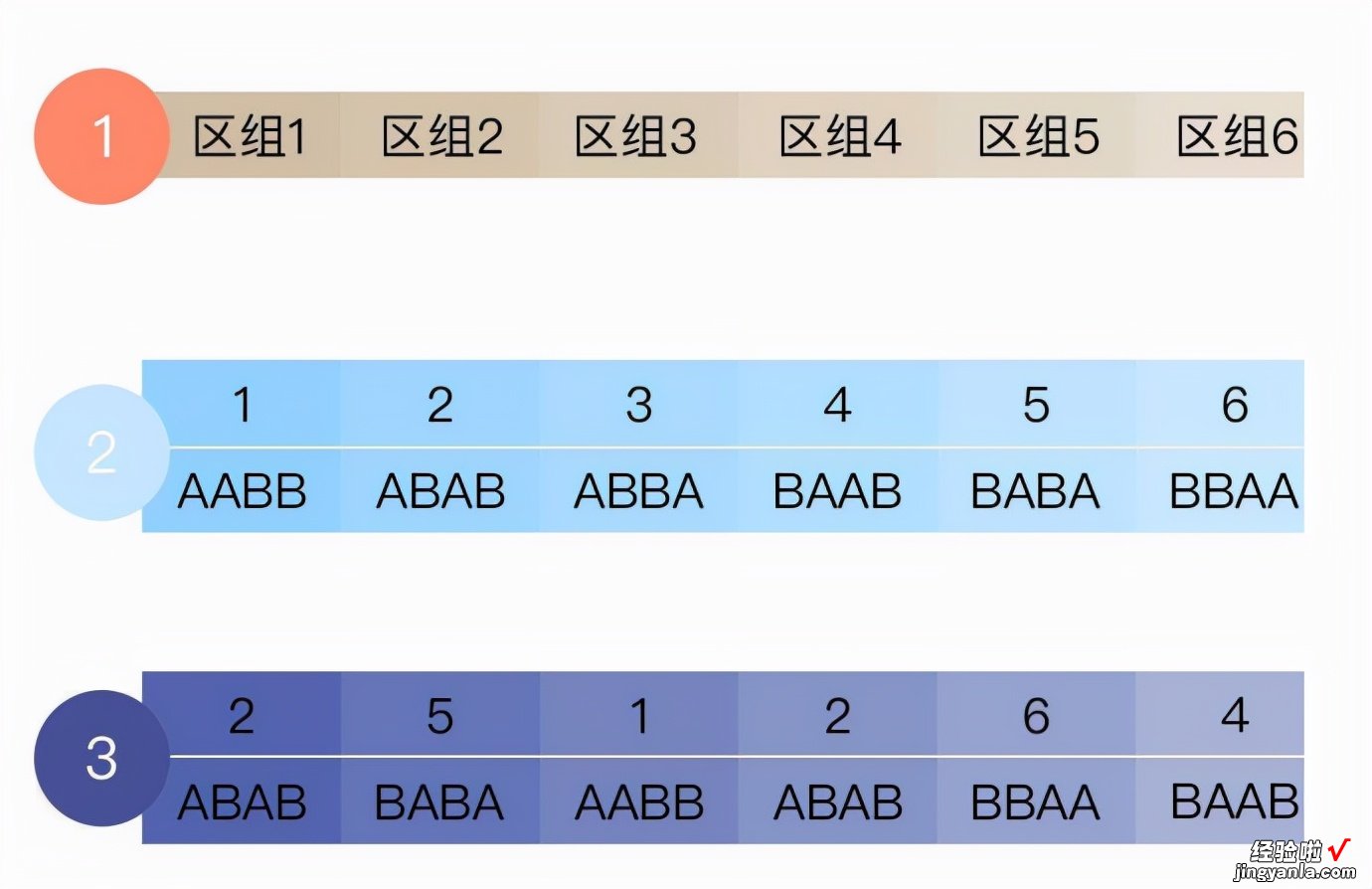
例2.以纳入40个研究对象为例,干预组:20名 , 对照组20名 。
- 设定区组长度:4;
- 研究对象排列方式:4个研究对象可以有6种排列方式;
- 区组随机排列:每次随机从数字1-6中抽取一个数字,加入第一个抽中的随机数字为3,与之相对应的排列方式为:ABBA,那么研究对象前4个(编号1、2、3、4)的入组情况为1=A、2=B、3=B、4=A 。
- 重复此过程直至收集到预先规定的受试者数 。
- 按照区组随机化过程如图所示 。
3.分层随机化
简单随机化可以使两组的基线特征可比,但可能会在个别关键因素间有差别 。简单随机化后如果某些关键因素(肿瘤的病理类型和分期等影响病人的预后的关键因素)在各组间的分布差异较大 , 则会影响到对药物效果的评价,可以使用分层随机化 。
分层随机化(Stratified Randomization):首先要根据研究对象某些重要的临床特征或危险因素分层(如年龄、性别、病情、疾病分期等);然后在每一层内进行简单随机分组;最后分别合并为试验组和对照组 。
注意:①多中心随机对照试验中 , 一般先按照中心分层,再在各中心内随机分组;②各中心内,可考虑再按照某些重要协变量分层 。各层内可采用区组随机化,保证该中心的试验组和对照组研究对象的数量相等 。这样整个研究的分组方案就是分层区组随机化 。③分层因素不宜过多,否则个别亚组内的研究对象数量将很少甚至没有 。此时,可采用动态随机化 。
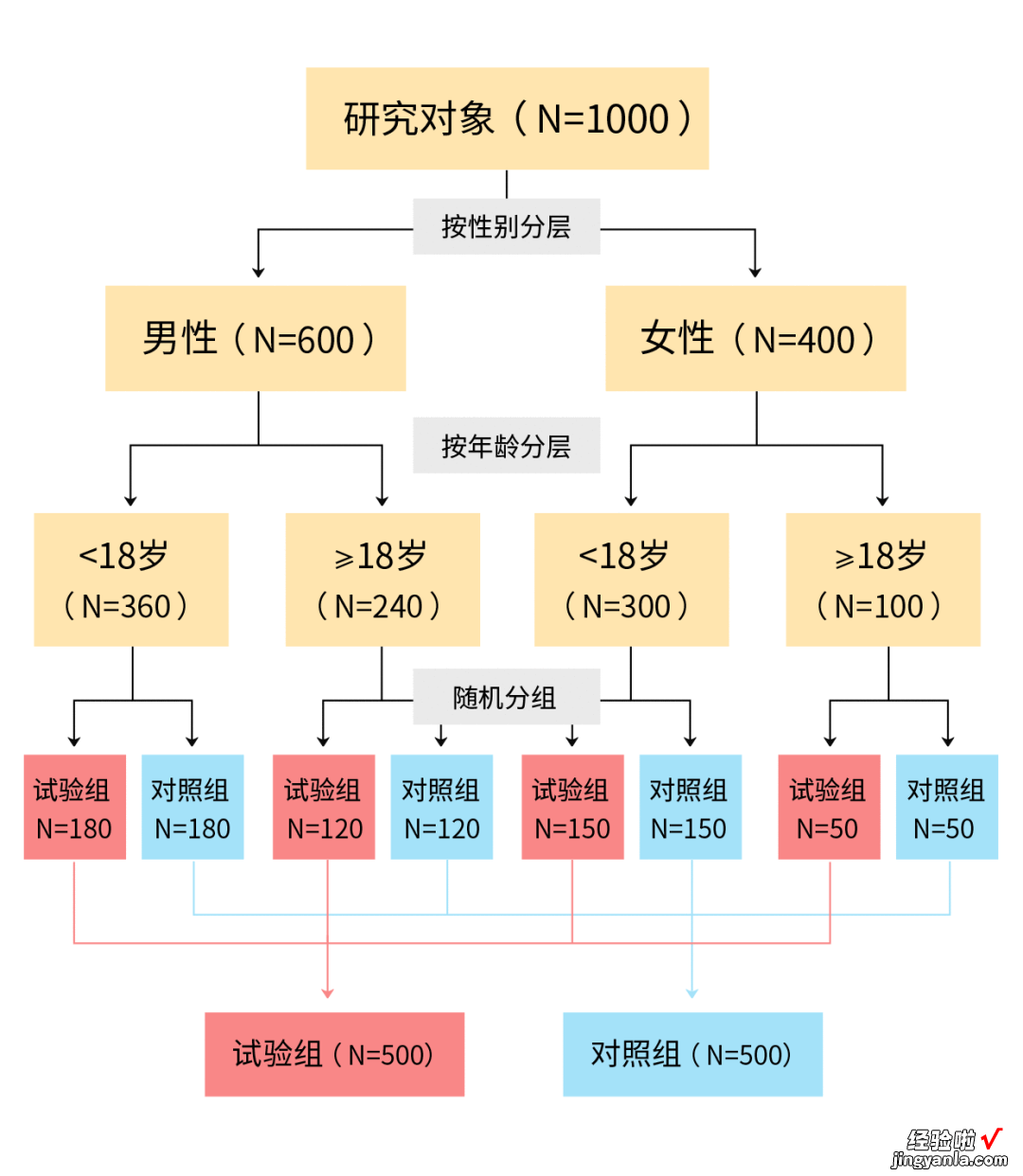
例3.某研究计划纳入1000例研究对象 。研究者认为不同性别和年龄之间,疾病预后的差别较大 。
- 将研究对象先按性别分组;
- 再在男性和女性中 , 按照年龄分组 。
- 随机分组方案流程图如下 。
2.分组隐匿
分组隐匿(Allocation Concealment):可以解释为一种防止随机分组方案提前解密的方法 。它是随机分组的必要条件,没有进行分组隐匿,不能起到避免选择偏倚的作用 。它可以解释为一种防止随机分组方案提前解密的方法 。
常见隐匿方法:有信封法、中心随机法等 。中心随机法适用于大型多中心研究;信封法适用于单中心小样本的临床研究 。
例4(信封法):在例1简单随机化分组中,我们已经设计好随机序列 。然后,采用随机信封法进行分组隐匿 。将每个分组方案装入一个不透光的信封,采用按顺序编码、不透光、密封的信封,信封外写上编码,密封好交给研究者 。待所有对象进入研究后,将调查对象编号 , 再打开相应编号的信封,按照信封的方式进行干预 。这样就可以说做到了分组隐匿 。
【听倦了的随机分组,原来是这么回事儿】
