如何爬一个网站的数据?爬取网络数据大家称之为网络爬行 收集页面以创建索引或集合 。另一方面,网络抓取下载页面以提取一组特定的数据用于分析目的,例如,产品详细信息、定价信息、SEO 数据或任何其他数据集 。

怎么实现快速爬取一个网站的数据,今天就教给大家一个方法 。不需要你懂任何技术,只要你会点鼠标,就能爬取网站的任意数据!从此告别复复制和粘贴的工作,爬取的数据可导出为Txt文档 、Excel表格、MySQL、SQLServer、 SQlite、Access、HTML网站等(PS:如果你爬取的是英文数据还可以使用自动翻译 , 网站管理人员还可以实现自动采集发布)

什么是数据抓?。?
数据抓取的定义 , 通常与网络抓取混淆,是指您获取任何公开可用的数据,无论是在网络上还是在您的计算机上,并将找到的信息导入计算机上的任何本地文件 。这些数据有时也可以传送到另一个网站 。数据抓取是从网络获取数据的最有效方式之一,它不需要互联网进行 。

什么是网页抓?。?
网络抓取是指您获取任何公开可用的在线数据并将找到的信息导入计算机上的任何本地文件 。此处与数据抓取的主要区别在于网络抓取定义需要在互联网上进行 。你可以通过 免费爬取软件实现,程序猿也可以通过Python 技术来完成 。

一、 Web爬虫概述
网络爬虫是一种自动地抓取网页信息的程序 。它通过对网站的URL进行请求,并解析返回的HTML页面以获取目标数据 。爬虫用于数据收集、监测竞争对手、分析市场趋势等 。
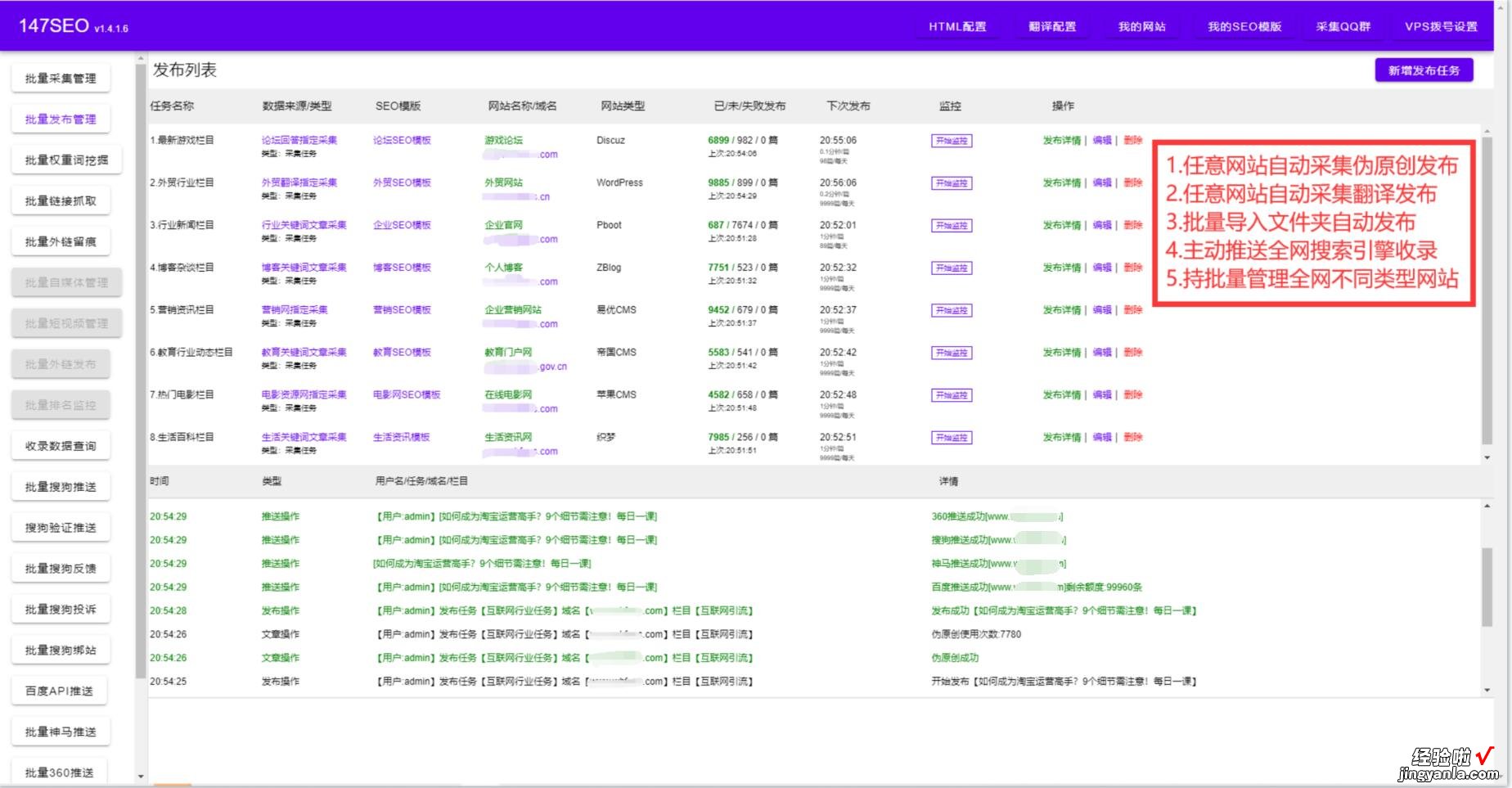
二、网站数据收集方法
常见网站数据收集方法包括:
1. 爬虫技术:通过编写代码对网站进行自动化访问和数据提取
2. 表单收集:通过在网站上的表单获取用户信息
3. 分析工具:使用网站分析工具,收集网站流量和用户行为数据
4. API调用:通过调用网站提供的API获取数据
5. 日志分析:分析网站服务器日志以获取用户行为数据 。

3. Python爬虫库使用
Python爬虫库是一种抓取Web数据的工具 , 通过对网页内容的分析,它从网页中提取有价值的数据 。常用的爬虫库有Scrapy、Beautiful Soup、Selenium等 。Scrapy是一个功能强大的爬虫框架,支持多线程、分布式爬取 。Beautiful Soup是一个解析HTML、XML文件的库 , 可以用于提取结构化数据 。Selenium是一个自动化测试工具,也可以用于爬虫 , 因为它可以模拟浏览器行为 。
4. 爬虫限制与避免
爬虫限制是指爬取网站内容的过程中,网站对爬虫的一些限制 。为了保护网站内容和防止爬取造成的服务器负担 , 网站通常会通过设定 IP 限制、User-Agent 反识别、验证码等手段来限制爬虫的行为 。避免爬虫限制的方法包括:使用代理 IP 进行爬取、分布式爬虫、设置合理的爬取频率、在 User-Agent 中模拟浏览器行为等 。

5. 网站数据分析与使用
【如何爬一个网站的数据-不懂技术也能快速爬取网页数据】网站数据分析是指对网站的访问数据进行收集、分析与可视化的过程 。目的是了解用户的行为习惯,分析访问