大部分公司还是需要员工自行整理发票填写报销单,并且打印电子发票后提交给财务才能报销 。如果发票多了会很浪费时间,让我们用Python写个程序来管理电子发票吧 。
个人发票管理功能点
- 发票自动识别,读取发票信息 。(前期只处理PDF电子发票)
- 批量导出识别的发票信息 。
- 合并多个发票文件到一个文件 。
- 提供可视化界面,支持C/S和B/S两种模式 。
- 添加到windows任务栏 。
- 发票分类 。根据报销类型对发票进行分类标注 。
- 发票抬头、税号、发票号等校验,排除错误抬头、避免出现重复发票 。
- 标注已经报销的发票 。
- 自动读取邮箱中的发票附件,并提取发票信息 。
- 支持图片格式增值税发票 。基于OCR识别发票 。
- 支持更多其他类型的发票 。
PDF格式电子发票信息读取
Python处理PDF的库很多,有PyMuPDF、PyPDF2、pdfminer、pdfplumber等 , 每个库都有不同的特点(这篇文章总结得比较全面,有兴趣的可以看看) 。【python进阶:PDF电子发票读取与合并】我选择用pdfplumber(https://github.com/jsvine/pdfplumber)这个库来读取发票内容,因为它可以方便的提取PDF中的文本、图片,重要的是它可以很好地提取表格 。
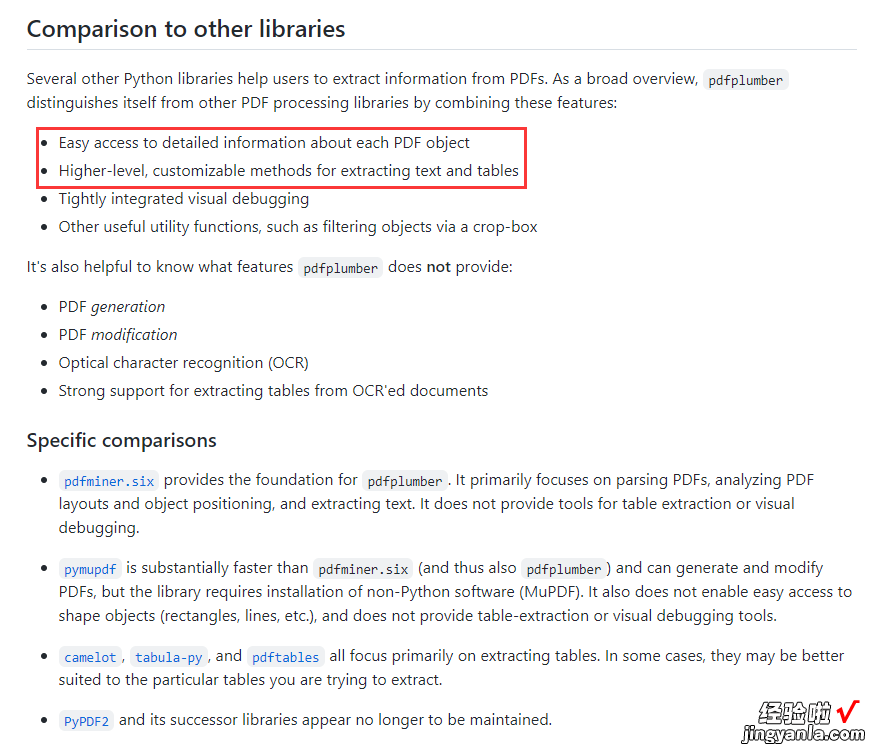
pdfplumber与其他库的比较
安装pdfplumber
pip install pdfplumber下面的示例代码将打印出pdfplumber读取的文本信息和表格信息,并且将pdf表格和文本框保存到图片查看读取效果 。另外,电子发票含有一个二维码,里面包含发票信息 , pdfplumber没有办法直接解析出图片,这里使用crop()函数截取图片区域,然后再用to_image()函数转成图片 。二维码图片可以用pyzbar等识别二维码的库解析,用于核对信息 。
import pdfplumber with pdfplumber.open(r"1.pdf") as pdf:# 读取第一页first_page = pdf.pages[0]# 转成图片,dpi设置为100im = first_page.to_image(resolution=100)# 画出表格边框和线条交点im.debug_tablefinder()# 画出文本边框im.draw_rects(first_page.extract_words())# 保存图片im.save(r"1.png")# 打印读取的文本print(first_page.extract_text())# 打印读取的表格print(first_page.extract_table())# 保存pdf中的图片for image in first_page.images:im = first_page.crop(bbox=(image['x0'],image['top'],image['x1'],image['bottom'])).to_image(resolution=100)im.save(f"{image['name']}.png")表格和文本识别区域
从上图可以看出pdfplumber识别发票表格的效果还是很好的,红色线是识别的表格,蓝色圆圈点是表格线条的交点 。
另外通过extract_text()打印出来的文本,我们分析可以发现,直接从文本中获取发票全部信息还是比较困难的(懒得打码就不放图了) , 很多信息混在一起 。这个换别的库提取文本也一样,都没有很好的效果 , 而且不同省份的发票PDF排版还不一样 , 如果不通过表格区域去获取文本,是没有办法解析发票全部信息的 。
最后,我们结合extract_text()和extract_table()分别获取发票头和发票表格中的信息 。
解析发票信息并导出到表格
解析发票比较简单,用正则表达式提取信息就可以了 。以发票表格上方的发票号等信息为例,通过extract_text()获取的文本来解析(需要注意的是不同地区发票的“冒号”有的是半角有的是全角):# 提取发票表格上方内容invoice.number = re.search(r'发票号码(:|:)(d )', text).group(2)invoice.date = re.search(r'开票日期(:|:)(.*)', text).group(2)invoice.machine_number = re.search(r'机器编号(:|:)(d )', text).group(2)invoice.code = re.search(r'发票代码(:|:)(d )', text).group(2)invoice.check_code = re.search(r'校验码(:|:)(d )', text).group(2)发票表格中的内容,则通过extract_table()获取的表格内容来解析 。以购买方为例,需要从指定的cell中去获取数据:
# 读取表格table = first_page.extract_table()# 表格为4行11列# ‘购买方’,内容,none,none,none,none,‘密码区’,密码,none,none,none# 货物名,none,规格,单位,数量,单价,none,none,金额,税率,税额# ‘价税合计’,none,金额,none,none,none,none,none,none , none , none# ‘销售方’ , 内容,none,none,none,none,‘备注’,备注,none,none,none# 购买方 purchaser = table[0][1].replace(" ", "")purchaser_name = re.search(r'名称(:|:)(. )', purchaser)invoice.purchaser_name = purchaser_name.group(2) if purchaser_name else ''purchaser_tax_number = re.search(r'纳税人识别号(:|:)(. )', purchaser)invoice.purchaser_tax_number = purchaser_tax_number.group(2) if purchaser_tax_number else ''purchaser_address = re.search(r'地址、电话(:|:)(. )', purchaser)invoice.purchaser_address = purchaser_address.group(2) if purchaser_address else ''purchaser_bank = re.search(r'开户行及账号(:|:)(. )', purchaser)invoice.purchaser_bank = purchaser_bank.group(2) if purchaser_bank else ''导出数据到excel
使用openpyxl可以很简单地将识别到的发票数据导出到excel文件 。workbook = openpyxl.Workbook()sheet=workbook[workbook.sheetnames[0]]# 导出开票日期、发票代码、发票号码、校验码、购买方名称和税号、销售方名称和税号、价格、税率、税额、价税合计、备注sheet.append(['开票日期','发票代码','发票号码','校验码','购买方名称','购买方税号','销售方名称','销售方税号','价格','税率','税额','价税合计','备注'])for i in range(row):invoice = invoices[i]sheet.append([invoice.date,invoice.code,invoice.number,invoice.check_code,invoice.purchaser_name,invoice.purchaser_tax_number,invoice.seller_name,invoice.seller_tax_number,invoice.total_amount,invoice.tax_rate,invoice.total_tax,invoice.total,invoice.remark])workbook.save(output_path)导出表格示例如下图:

合并发票文件
由于pdfplumber不能很好的编辑PDF文件 , 这里我们使用PyPDF4来处理PDF的合并,代码也很简单:from PyPDF4 import PdfFileMergermerger = PdfFileMerger()for invoice_path in invoice_paths:merger.append(invoice_path)merger.write(output_path)merger.close()为了节省纸张,有些公司会在一张A4纸打印2张发票,这里我们不去实现两张发票合并到一个页面的功能,这个可以在文件打印的时候选择一页打印多张PDF 。
源码
最后,干货必须带源码~python版本为3.8 , 需要安装的依赖包如下requirements.txt:
pdfplumber~=0.6.1PyPDF4~=1.27.0openpyxl~=3.0.7invoice.py
import pdfplumberfrom PyPDF4 import PdfFileMergerimport openpyxlimport re,time,osclass Invoice:def __init__(self):# 发票类型、发票号码、开票日期、机器编号、发票代码、校验码self.type=self.number=self.date=self.machine_number=self.code=self.check_code = ''# 收款人、复核、开票人self.payee=self.reviewer=self.drawer = ''# 购买方名称、纳税人识别号、地址电话、开户行及账号self.purchaser_name=self.purchaser_tax_number=self.purchaser_address=self.purchaser_bank = ''# 密码self.password = ''# 合计金额、合计税额、税率、价税合计self.total_amount=self.total_tax=self.tax_rate=self.total = ''# 销售方名称、纳税人识别号、地址电话、开户行及账号self.seller_name=self.seller_tax_number=self.seller_address=self.seller_bank = ''# 备注self.remark = ''# 解析PDF格式电子发票@staticmethoddef read_invoice(pdf_file: str) -> "Invoice":invoice = Invoice()try:with pdfplumber.open(pdf_file) as pdf:# 读取第一页first_page = pdf.pages[0]# 读取文本text = first_page.extract_text().replace(" ", "")# print(text)if '专用发票' in text:invoice.type = '专票'elif '普通发票' in text:invoice.type = '普票'else:raise Exception('未知发票类型或非发票文件')# 提取发票表格上方内容invoice.number = re.search(r'发票号码(:|:)(d )', text).group(2)invoice.date = re.search(r'开票日期(:|:)(.*)', text).group(2)invoice.machine_number = re.search(r'机器编号(:|:)(d )', text).group(2)invoice.code = re.search(r'发票代码(:|:)(d )', text).group(2)invoice.check_code = re.search(r'校验码(:|:)(d )', text).group(2)# 提取发票表格下方内容,全在一行里match = re.search(r'.*收款人(:|:)(.*)复核(:|:)(.*)开票人(:|:)(.*)销售', text)invoice.payee = match.group(2)invoice.reviewer = match.group(4)invoice.drawer = match.group(6)# 读取表格table = first_page.extract_table()# 表格为4行11列# ‘购买方’ , 内容,none,none,none,none,‘密码区’,密码,none,none,none# 货物名 , none,规格,单位 , 数量,单价,none,none,金额,税率,税额# ‘价税合计’,none,金额 , none,none,none,none,none,none,none,none# ‘销售方’,内容,none,none,none,none,‘备注’,备注,none,none,noneif table and len(table)==4:# 购买方purchaser = table[0][1].replace(" ", "")purchaser_name = re.search(r'名称(:|:)(. )', purchaser)invoice.purchaser_name = purchaser_name.group(2) if purchaser_name else ''purchaser_tax_number = re.search(r'纳税人识别号(:|:)(. )', purchaser)invoice.purchaser_tax_number = purchaser_tax_number.group(2) if purchaser_tax_number else ''purchaser_address = re.search(r'地址、电话(:|:)(. )', purchaser)invoice.purchaser_address = purchaser_address.group(2) if purchaser_address else ''purchaser_bank = re.search(r'开户行及账号(:|:)(. )', purchaser)invoice.purchaser_bank = purchaser_bank.group(2) if purchaser_bank else ''# 密码区invoice.password = table[0][7].replace("n", "")# 合计金额、税额invoice.total_amount = table[1][8].split("n")[-1].replace("¥", "").replace(" ", "").replace(",", "")invoice.total_amount = float(invoice.total_amount)# 注意有的发票税额为0是'*',无法直接转成数值invoice.total_tax = table[1][10].split("n")[-1].replace("¥", "").replace(" ", "").replace("*", "0").replace(",", "")invoice.total_tax = float(invoice.total_tax) if invoice.total_tax else 0# 税率,一般一张发票中货品税率一致;也可以用(总税额/总金额)计算税率invoice.tax_rate = table[1][9].split("n")[-1].replace(" ", "").replace("%", "").replace("*", "0")invoice.tax_rate = float(invoice.tax_rate)/100 if invoice.tax_rate else 0# invoice.tax_rate = invoice.total_tax / invoice.total_amount# 价税合计,解析或计算invoice.total = re.search(r'. ¥(. )', table[2][2]).group(1).replace(" ", "").replace(",", "")invoice.total = float(invoice.total)# invoice.total = invoice.total_taxinvoice.total_amount# 销售方seller = table[3][1].replace(" ", "")invoice.seller_name = re.search(r'名称(:|:)(. )', seller).group(2)invoice.seller_tax_number = re.search(r'纳税人识别号(:|:)(. )', seller).group(2)seller_address = re.search(r'地址、电话(:|:)(. )', seller)invoice.seller_address = seller_address.group(2) if seller_address else ''seller_bank = re.search(r'开户行及账号(:|:)(. )', seller)invoice.seller_bank = seller_bank.group(2) if seller_bank else ''# 备注invoice.remark = table[3][7].replace("n", "")except Exception as e:print(pdf_file, e)return invoice#导出到excel@staticmethoddef export_to_excel(invoices:"list[Invoice]", output_path:str):row = len(invoices) if invoices else 0if row == 0:print("没有可导出的数据")returntry:workbook = openpyxl.Workbook()sheet=workbook[workbook.sheetnames[0]]# 导出开票日期、发票代码、发票号码、校验码、购买方名称和税号、销售方名称和税号、价格、税率、税额、价税合计、备注sheet.append(['开票日期','发票代码','发票号码','校验码','购买方名称','购买方税号','销售方名称','销售方税号','价格','税率','税额','价税合计','备注'])for i in range(row):invoice = invoices[i]sheet.append([invoice.date,invoice.code,invoice.number,invoice.check_code,invoice.purchaser_name,invoice.purchaser_tax_number,invoice.seller_name,invoice.seller_tax_number,invoice.total_amount,invoice.tax_rate,invoice.total_tax,invoice.total,invoice.remark])workbook.save(output_path)except Exception as e:print('导出到excel失败', e)# 合并pdf@staticmethoddef merge_pdf(invoice_paths:"list[str]", output_path:str):if len(invoice_paths) == 0:print("没有可合并的pdf")returntry:merger = PdfFileMerger()for invoice_path in invoice_paths:merger.append(invoice_path)merger.write(output_path)merger.close()except Exception as e:print('合并pdf失败', e)if __name__ == '__main__':# 发票所在文件夹 , 使用绝对路径path = r'E:playgroundpython_toolspdf'# 输出文件路径output_path = os.path.join(path, 'output')if not os.path.exists(output_path):os.makedirs(output_path)# 发票内容列表invoices = []# 发票文件路径列表invoice_paths = []#列出目录的下所有文件lists = os.listdir(path)for item in lists:if item.endswith('.pdf'):item = os.path.join(path, item)invoice = Invoice.read_invoice(item)# 仅保存解析成功的pdfif invoice and invoice.type:invoices.append(invoice)invoice_paths.append(item)# 导出发票内容到excelInvoice.export_to_excel(invoices, f'{output_path}/invoice_{time.strftime("%Y%m%d_%H%M%S", time.localtime())}.xlsx')# 合并发票到一个pdfInvoice.merge_pdf(invoice_paths, f'{output_path}/merged_invoice_{time.strftime("%Y%m%d_%H%M%S", time.localtime())}.pdf')